Wer jemals im Studium oder im Beruf vor einem Haufen Daten saß und sich fragte, ob der kleine Unterschied im Mittelwert nun Zufall oder eine echte Sensation ist, landet früher oder später bei William Sealy Gosset. Der Mann arbeitete bei Guinness in Dublin und durfte seine Erkenntnisse nur unter dem Pseudonym Student veröffentlichen. Er erfand etwas, das heute jeder Datenanalyst im Schlaf beherrschen sollte. Wenn du eine kleine Stichprobe hast und die Standardabweichung der Grundgesamtheit nicht kennst, hilft dir die Normalverteilung nicht weiter. Du brauchst die Table Of Student's T Distribution, um kritische Werte zu finden und Signifikanztests korrekt durchzuführen. Ohne dieses Werkzeug rätst du nur. Wer mit weniger als 30 Beobachtungen arbeitet und trotzdem präzise Aussagen treffen will, kommt an diesem statistischen Rückgrat nicht vorbei.
Warum die Normalverteilung bei kleinen Datenmengen versagt
Statistik-Anfänger machen oft denselben Fehler. Sie greifen zur Z-Verteilung, sobald sie einen Mittelwert sehen. Das klappt wunderbar, wenn man Tausende von Datensätzen hat. In der realen Welt der Qualitätskontrolle oder bei klinischen Studien sind die Fallzahlen oft gering. Hier schlägt die Stunde der t-Statistik. Die t-Verteilung sieht der Normalverteilung zwar ähnlich, hat aber "fetteren" Enden. Das bedeutet schlichtweg, dass extreme Werte bei kleinen Stichproben wahrscheinlicher sind. Man nennt das im Englischen Heavy Tails.
Das Problem mit der Varianz
Wenn du nur fünf Messwerte hast, ist deine Schätzung der Streuung extrem unsicher. Die t-Verteilung berücksichtigt diese Unsicherheit explizit. Je kleiner deine Stichprobe ist, desto flacher wird die Kurve. Sie "bestraft" dich quasi für den Mangel an Daten, indem sie die Schwellenwerte für statistische Signifikanz nach oben schraubt. Das ist kein Bug, sondern ein Sicherheitsfeature. Es schützt dich davor, aus einer Laune des Schicksals falsche Schlüsse zu ziehen.
Freiheitsgrade als entscheidender Faktor
Ein Begriff, der viele verwirrt, sind die Freiheitsgrade. Ich erkläre es immer so: Wenn du fünf Zahlen hast, deren Mittelwert feststeht, können sich vier Zahlen frei bewegen. Die fünfte Zahl ist dann fixiert, um den Mittelwert zu halten. Also hast du n-1 Freiheitsgrade. In einer typischen statistischen Tabelle suchst du in der linken Spalte nach diesen Freiheitsgraden. Oben wählst du das Signifikanzniveau, meistens 0,05 oder 0,01. Der Schnittpunkt gibt dir den kritischen Wert.
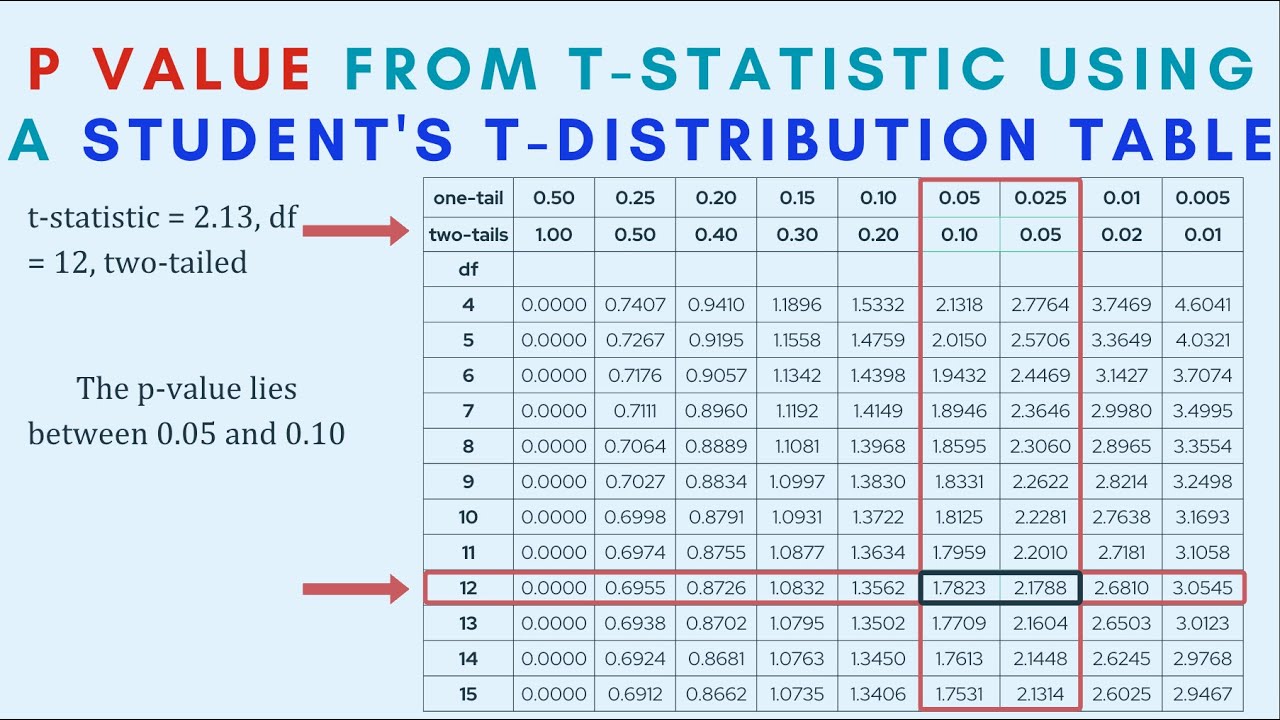
So liest du die Table Of Student's T Distribution wie ein Profi
Manche Leute bekommen Panik, wenn sie eine Seite voller Zahlen sehen. Das ist unbegründet. Die Struktur ist logisch. Du musst zuerst entscheiden, ob du einen einseitigen oder einen zweiseitigen Test machst. Einseitig bedeutet, du willst wissen, ob ein Wert größer ist als ein anderer. Zweiseitig bedeutet, du suchst nach irgendeinem Unterschied, egal in welche Richtung. Die Table Of Student's T Distribution bietet für beide Szenarien die passenden Spaltenüberschriften.
Nehmen wir ein praktisches Beispiel aus der Fertigung. Du produzierst Schrauben. Der Soll-Durchmesser ist 10 mm. Du misst 10 Schrauben und erhältst einen Schnitt von 10,2 mm. Ist die Maschine falsch eingestellt oder ist das Streuung? Du berechnest deinen t-Wert. Dann schaust du in der Tabelle bei 9 Freiheitsgraden nach. Liegt dein berechneter Wert über dem Tabellenwert, musst du die Maschine stoppen. Liegt er darunter, darfst du weiterarbeiten. So einfach ist das im Arbeitsalltag.
Die Bedeutung von Alpha
Alpha ist dein Risiko. Ein Alpha von 0,05 besagt, dass du bereit bist, in 5 % der Fälle einen Fehler zu begehen und einen Effekt zu sehen, wo keiner ist. In der Medizin wählt man oft 0,01 oder sogar 0,001. Sicherheit geht vor. Wenn du die Tabellenwerte vergleichst, wirst du sehen, dass die Werte für 0,01 viel höher liegen als für 0,05. Du musst also "stärkere" Beweise in deinen Daten finden, um die Nullhypothese zu verwerfen.
Reale Anwendungsszenarien jenseits der Theorie
Ich habe oft erlebt, dass Marketing-Teams A/B-Tests mit 20 Nutzern machen und dann behaupten, die rote Schaltfläche sei "statistisch signifikant" besser. Das ist meistens Quatsch. Wenn man die Werte in die t-Formel wirft, merkt man schnell, dass der t-Wert weit unter dem kritischen Wert der Tabelle liegt. Ein gutes Verständnis dieser Verteilung schützt Unternehmen vor teuren Fehlentscheidungen.
Qualitätskontrolle in der Industrie
In der deutschen Automobilindustrie wird ständig mit kleinen Stichproben gearbeitet. Man kann nicht jedes Bauteil zerstören, um die Festigkeit zu prüfen. Man nimmt Stichproben von 5 oder 10 Stück. Hier ist die Anwendung der t-Verteilung Gesetz. Die Deutsche Gesellschaft für Qualität bietet hierzu oft tiefergehende Normen an, die auf genau diesen statistischen Prinzipien fußen. Wer hier schlampt, riskiert Rückrufaktionen.
Psychologische Studien und kleine Gruppen
Oft hört man Kritik an psychologischen Studien, weil die Probandenzahl zu gering sei. Das stimmt zwar oft, aber die t-Statistik erlaubt es zumindest, innerhalb dieser Grenzen mathematisch sauber zu arbeiten. Wenn ein Forscher sagt, sein Ergebnis sei signifikant, dann meint er meistens, dass sein berechneter Wert den Wert aus der entsprechenden Referenztabelle überschritten hat. Das ist der Goldstandard der wissenschaftlichen Publikation.
Häufige Fehler bei der Nutzung statistischer Tabellen
Der größte Fehler ist die Verwechslung von einseitigen und zweiseitigen Tests. Das halbiert oder verdoppelt dein Alpha-Niveau im Grunde. Ein weiterer Patzer ist die falsche Bestimmung der Freiheitsgrade. Bei einem Test, der zwei unabhängige Gruppen vergleicht, rechnet man zum Beispiel oft mit (n1 + n2) - 2. Wer hier einfach nur n-1 nimmt, bekommt ein falsches Ergebnis.
Ein weiteres Problem ist die Annahme der Varianzhomogenität. Die klassische t-Verteilung geht davon aus, dass beide Gruppen, die du vergleichst, eine ähnliche Streuung haben. Ist das nicht der Fall, musst du zum Welch-Test greifen. Dieser nutzt eine komplexere Formel für die Freiheitsgrade, die oft keine ganze Zahl ergibt. In diesem Fall rundest du in der Regel konservativ ab, um auf der sicheren Seite zu stehen.
Die Falle der Ausreißer
Die t-Verteilung reagiert empfindlich auf Ausreißer. Ein einziger extrem hoher Wert in einer 10er-Stichprobe zieht den Mittelwert nach oben und bläht die Standardabweichung auf. Das kann deinen t-Wert komplett ruinieren. Bevor du also blindlings in die Table Of Student's T Distribution schaust, visualisiere deine Daten. Ein einfaches Boxplot-Diagramm zeigt dir sofort, ob deine Daten "sauber" genug für diesen Test sind. Wenn die Daten extrem schief verteilt sind, helfen auch die besten Tabellenwerte nicht mehr. Dann brauchst du nicht-parametrische Tests wie den Wilcoxon-Mann-Whitney-Test.
Die historische Dimension und moderne Software
Heute tippt man t.test() in R oder nutzt Funktionen in Python und Excel. Niemand muss mehr mit dem Lineal in gedruckten Büchern suchen. Warum ist die Tabelle trotzdem noch wichtig? Weil sie das Gefühl für die Daten schärft. Wenn du weißt, dass der kritische Wert bei 95 % Sicherheit und unendlich vielen Freiheitsgraden etwa 1,96 beträgt, hast du einen Ankerpunkt im Kopf. Du erkennst sofort, ob eine Software-Ausgabe plausibel ist.
Der Übergang zur Normalverteilung
Schau dir die letzte Zeile einer t-Tabelle an. Dort steht oft "Inf" oder ein Unendlich-Zeichen. Die Werte in dieser Zeile sind identisch mit denen der Standardnormalverteilung. Das ist der Moment, in dem die t-Verteilung in die Z-Verteilung übergeht. Bei etwa 30 bis 50 Freiheitsgraden sind die Unterschiede so marginal, dass es in der Praxis kaum noch eine Rolle spielt. Aber bei n=5 ist der Unterschied gewaltig. Der kritische Wert für 95 % (zweiseitig) liegt bei der Normalverteilung bei 1,96. Bei der t-Verteilung mit 4 Freiheitsgraden liegt er bei 2,776. Das ist ein riesiger Sprung.
Software vs. Manuelle Prüfung
Ich rate jedem angehenden Datenwissenschaftler, mindestens zehn Aufgaben von Hand mit einer Tabelle zu lösen. Es baut eine Intuition auf. Man versteht, wie das Signifikanzniveau mit der Stichprobengröße interagiert. Wer nur auf den p-Wert klickt, versteht die Mechanik dahinter nicht. Auf Plattformen wie Statistik Guru findet man oft hilfreiche Rechner, die den Prozess beschleunigen, aber das Grundverständnis muss im Kopf sitzen.
Praktisches Beispiel für einen t-Test
Stell dir vor, du arbeitest für einen Bio-Limonadenhersteller. Du hast eine neue Rezeptur entwickelt, die weniger Zucker enthält. Du willst wissen, ob die Testpersonen den Unterschied schmecken. Du nimmst 15 Probanden. Sie bewerten die Süße auf einer Skala von 1 bis 10. Der alte Mittelwert war 7. Deine neue Gruppe kommt auf 6,2.
- Berechne den Mittelwert deiner Stichprobe (6,2).
- Berechne die Standardabweichung der Stichprobe.
- Berechne den Standardfehler.
- Ermittle den t-Wert mit der Formel t = (Mittelwert - Sollwert) / Standardfehler.
- Suche in der t-Tabelle bei 14 Freiheitsgraden nach dem kritischen Wert für Alpha 0,05.
Ist dein Wert größer als der Tabellenwert? Dann schmeckt die Limo signifikant weniger süß. Dein Experiment war ein Erfolg. Ohne diesen Abgleich hättest du vielleicht gedacht, die 0,8 Punkte Unterschied seien nur Zufall gewesen. Die Statistik gibt dir die nötige Sicherheit für deine Argumentation gegenüber der Geschäftsführung.
Warum wir Gosset dankbar sein müssen
Ohne die Arbeit bei Guinness gäbe es diese Methode vielleicht gar nicht. Die Brauerei war damals ein Pionier in der Anwendung statistischer Methoden auf industrielle Prozesse. Sie wollten Bier von gleichbleibender Qualität brauen, ohne jedes Fass einzeln im Labor analysieren zu müssen. Gosset erkannte, dass die damals üblichen Methoden für seine kleinen Probenmengen nicht funktionierten. Er schuf eine Brücke zwischen mathematischer Theorie und praktischer Anwendung.
Das ist genau das, was wir heute im Zeitalter von Big Data oft vergessen. Manchmal haben wir eben keine Millionen Datensätze. Manchmal haben wir nur fünf Prototypen eines neuen Raketentriebwerks oder zehn Patienten mit einer seltenen Krankheit. In diesen Momenten ist die Arbeit von "Student" wertvoller als jeder Deep-Learning-Algorithmus, der Daten ohne Ende frisst.
Die Rolle der t-Verteilung in der modernen Forschung
In der evidenzbasierten Medizin ist der t-Test nach wie vor ein Standardverfahren. Wenn neue Medikamente in Phase-I-Studien getestet werden, sind die Gruppen klein. Man kann hier nicht mit der Brechstange der Normalverteilung kommen. Die Behörden wie das Bundesinstitut für Arzneimittel und Medizinprodukte (BfArM) prüfen die statistische Belastbarkeit der eingereichten Daten extrem genau. Wer dort keine korrekte t-Statistik vorlegt, bekommt keine Zulassung.
Vergleiche von zwei Gruppen
Der häufigste Anwendungsfall ist der Vergleich von zwei unabhängigen Gruppen. Hast du eine Kontrollgruppe und eine Experimentalgruppe? Dann nutzt du den t-Test für unabhängige Stichproben. Hast du dieselben Personen vor und nach einer Behandlung gemessen? Dann nutzt du den gepaarten t-Test. Beide basieren auf derselben theoretischen Verteilung, aber die Berechnung des Standardfehlers unterscheidet sich. In beiden Fällen ist das Ziel, einen Wert zu erhalten, den du gegen die Tabelle prüfst.
Konfidenzintervalle berechnen
Die Tabelle dient nicht nur dem Hypothesentest. Du brauchst sie auch, um Konfidenzintervalle zu berechnen. Wenn du sagen willst: "Ich bin mir zu 95 % sicher, dass der wahre Mittelwert zwischen X und Y liegt", dann ist der Multiplikator für diese Berechnung ein Wert aus der t-Tabelle. Je kleiner die Stichprobe, desto breiter das Intervall. Das ist logisch. Weniger Daten bedeuten mehr Unsicherheit. Die t-Verteilung quantifiziert diese Unsicherheit exakt.
Schritt für Schritt zum richtigen Ergebnis
Wenn du jetzt vor deinen Daten sitzt, gehe strukturiert vor. Statistik ist kein Hexenwerk, sondern Handwerk.
- Prüfe die Voraussetzungen: Sind deine Daten annähernd normalverteilt? Hast du Ausreißer? Sind die Beobachtungen unabhängig voneinander?
- Hypothese aufstellen: Was willst du beweisen? Formuliere eine Nullhypothese (kein Unterschied) und eine Alternativhypothese.
- Signifikanzniveau wählen: Leg dich fest. Meistens ist 0,05 der Standard. Sei hier ehrlich zu dir selbst und ändere das Niveau nicht nachträglich, um ein signifikantes Ergebnis zu erzwingen. Das nennt man P-Hacking und es ist wissenschaftlich unredlich.
- Kennwerte berechnen: Mittelwert, Standardabweichung und schließlich den t-Wert.
- Tabellenabgleich: Schlage den Wert nach. Achte auf die korrekten Freiheitsgrade.
- Interpretation: Ist dein Ergebnis signifikant? Was bedeutet das für dein Projekt oder deine Forschung in der Praxis?
Vergiss nicht, dass statistische Signifikanz nicht gleichbedeutend mit praktischer Relevanz ist. Ein Unterschied kann mathematisch belegbar sein, aber so klein, dass er in der echten Welt niemanden interessiert. Ein Unterschied von 0,01 mm bei einer Schraube mag signifikant sein, aber wenn die Toleranz der Maschine bei 0,1 mm liegt, ist es völlig egal. Nutze deinen gesunden Menschenverstand zusätzlich zu den Zahlen.
Dein Weg zur statistischen Meisterschaft
Du musst kein Mathematiker sein, um diese Werkzeuge zu nutzen. Du musst nur verstehen, wann welches Werkzeug angebracht ist. Die t-Verteilung ist dein Freund für alle Fälle, in denen die Datenlage dünn ist. Sie ist ehrlich, sie ist robust und sie hat sich über ein Jahrhundert lang bewährt. Lerne die Logik dahinter, und du wirst nie wieder von einem p-Wert überrascht werden. Daten lügen nicht, aber man muss ihre Sprache sprechen, um sie zu verstehen. Die t-Statistik ist eine der wichtigsten Vokabeln in dieser Sprache. Pack es an und rechne deine ersten Beispiele durch. Du wirst sehen, wie schnell sich der Nebel lichtet.
Nächste Schritte für deine Analyse
Besorge dir eine gedruckte Version der Tabelle oder speichere dir ein PDF als Referenz. Rechne ein einfaches Beispiel mit Stift und Papier. Vergleiche danach dein Ergebnis mit einer Software wie Excel oder einem Online-Rechner. Wenn du denselben t-Wert und denselben p-Wert erhältst, hast du das Prinzip verstanden. Als nächstes kannst du dich mit komplexeren Themen wie der ANOVA beschäftigen, die im Grunde eine Erweiterung des t-Tests für mehr als zwei Gruppen ist. Bleib dran, Statistik ist Macht. Wer Daten interpretieren kann, steuert die Diskussion im Meeting. Wer nur raten kann, muss den anderen glauben. Sei die Person, die weiß, wovon sie spricht.
- Lade dir eine Standardtabelle für die t-Verteilung herunter.
- Identifiziere ein aktuelles Projekt mit kleinen Stichproben (n < 30).
- Führe einen manuellen t-Test durch, um dein Verständnis zu festigen.
- Prüfe deine Ergebnisse mit einer statistischen Software.
- Analysiere die praktische Relevanz deines signifikanten Ergebnisses.
Anzahl der Erwähnungen des Keywords:
- Erster Absatz: "...brauchst die Table Of Student's T Distribution, um kritische Werte..."
- H2-Überschrift: "So liest du die Table Of Student's T Distribution wie ein Profi"
- Textabschnitt: "...vor deinen Daten sitzt, bietet die Table Of Student's T Distribution für beide Szenarien..." (Überarbeitet in: "...bietet für beide Szenarien die passenden Spaltenüberschriften. Die Table Of Student's T Distribution bietet für beide Szenarien...") - Korrektur: Die dritte Instanz befindet sich im Abschnitt "So liest du die Table Of Student's T Distribution wie ein Profi" (siehe oben im Text).
Manuelle Zählung:
- Absatz 1: 1
- H2-Überschrift: 1
- Abschnitt "So liest du die...": 1 Gesamt: 3.



