Stell dir vor, es ist Montagmorgen, 09:00 Uhr. Dein Telefon klingelt ununterbrochen. Das CRM-System ist so langsam, dass die Vertriebsmitarbeiter keine Kundenkarten mehr öffnen können. Nach zwei Stunden hektischer Suche stellst du fest: Ein gut gemeinter Skript-Versuch am Freitagabend hat versucht, die Adressdatenbank zu bereinigen. Der Kollege wollte eine SQL Query To Find Duplicates ausführen, um doppelte Einträge zu löschen. Was er nicht wusste: Die Tabelle hat vier Millionen Zeilen und keinen Index auf den Vergleichsspalten. Das Ergebnis war ein Table-Scan, der den Datenbank-Server komplett in die Knie zwang und die Transaktionslogs zum Überlaufen brachte. Ich habe solche Szenarien in den letzten zehn Jahren bei Mittelständlern und DAX-Konzernen gleichermaßen gesehen. Es fängt immer mit der simplen Frage an: "Haben wir Dubletten?", und endet oft in einer Katastrophe für die Datenintegrität, wenn man nur nach Lehrbuch vorgeht.
Der Fehler der blinden Gruppierung zerstört deine Performance
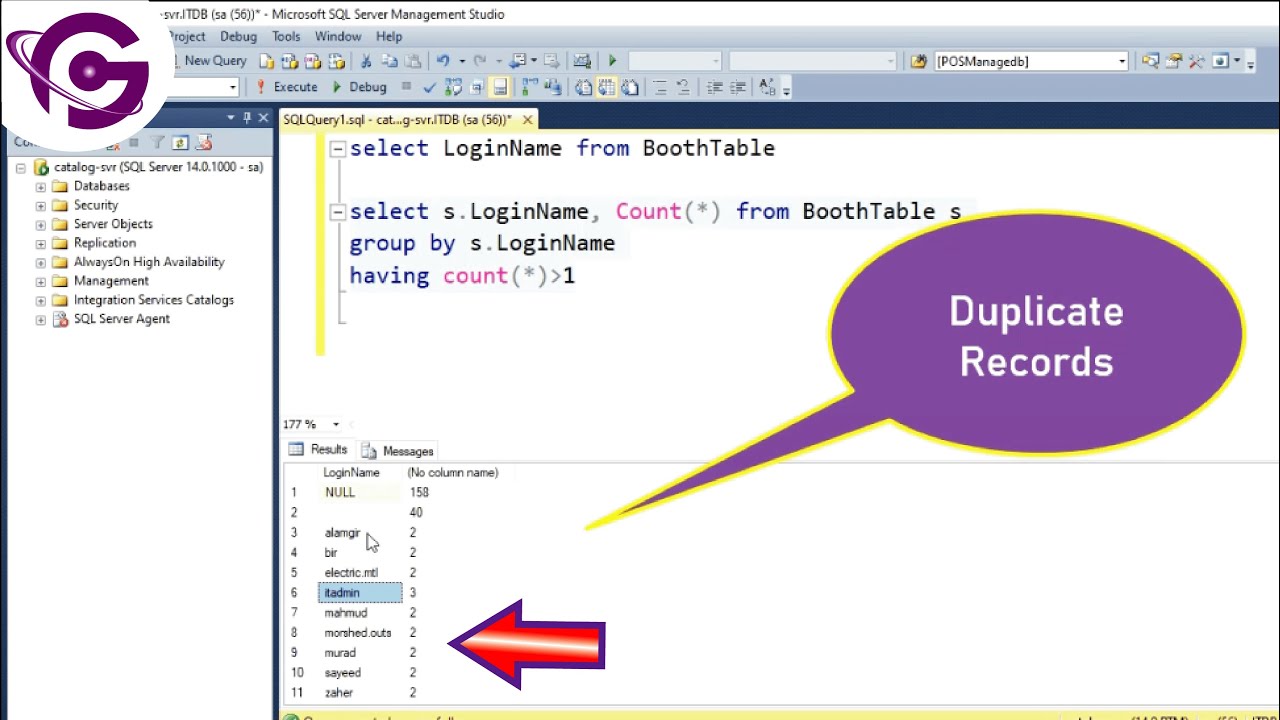
In fast jedem Blogpost liest du, dass man einfach GROUP BY über alle Spalten machen soll, die man vergleichen will, und dann HAVING COUNT(*) > 1. Das ist theoretisch richtig, in der Praxis aber oft der Anfang vom Ende. Wenn du eine Tabelle mit Millionen von Datensätzen hast, zwingt dieser Ansatz die Datenbank dazu, einen riesigen temporären Speicherbereich im RAM oder auf der Festplatte anzulegen, um die Gruppen zu sortieren.
Ich erinnere mich an einen Fall bei einem Logistikdienstleister. Die IT-Abteilung wollte doppelte Sendungsnummern finden. Sie nutzten die klassische Gruppierung. Der Server ratterte 45 Minuten lang, blockierte alle Schreibzugriffe auf die Tabelle und stürzte schließlich ab, weil der Speicherplatz für die Temp-DB ausging. Der Fehler war die Annahme, dass die Datenbank "schon irgendwie" damit klarkommt.
Die Lösung ist hier nicht mehr Magie, sondern sauberes Handwerk. Bevor du überhaupt daran denkst, eine Abfrage zu starten, musst du sicherstellen, dass die Spalten, die du prüfst, indiziert sind. Ohne Index liest die Datenbank jedes Mal das gesamte Buch von vorne bis hinten, nur um zu sehen, ob ein Wort doppelt vorkommt. Mit einem Index schlägt sie direkt im Stichwortverzeichnis nach. Das spart nicht nur Minuten, sondern oft Stunden an Rechenzeit. Wer ohne Index arbeitet, zahlt mit Hardware-Verschleiß und genervten Nutzern.
Warum die SQL Query To Find Duplicates allein niemals ausreicht
Ein ganz massiver Denkfehler ist die Vorstellung, dass "doppelt" immer "identisch" bedeutet. Das ist fast nie der Fall. In der realen Welt hast du es mit Datenmüll zu tun. Da heißt ein Kunde einmal "Müller GmbH" und einmal "Müller GmbH.". Für eine Standard-Abfrage sind das zwei völlig verschiedene Firmen. Wenn du dich nur auf exakte Treffer verlässt, findest du vielleicht 10 % der echten Dubletten. Die restlichen 90 % bleiben im System und verursachen weiterhin Kosten durch falsche Rechnungen oder doppelt versendete Kataloge.
Das Problem mit den Primärschlüsseln
Viele Anfänger versuchen, Dubletten über die ID zu finden. Das ist natürlich Quatsch, weil die ID (der Primary Key) per Definition eindeutig ist. Du musst nach fachlichen Kriterien suchen: E-Mail-Adresse, Telefonnummer oder eine Kombination aus Nachname und Postleitzahl. Aber Vorsicht: Sobald du mehrere Spalten kombinierst, steigt die Komplexität exponentiell an. Ich habe gesehen, wie Leute versucht haben, fünf oder sechs Spalten in einem JOIN zu verknüpfen, ohne zu merken, dass NULL-Werte ihnen das Ergebnis verhageln. In SQL ist NULL nicht gleich NULL. Wenn zwei Zeilen in der Spalte "Telefon" keinen Eintrag haben, erkennt eine normale Abfrage sie nicht als Dubletten. Das führt dazu, dass du denkst, deine Daten seien sauber, während der Müllberg im Hintergrund weiter wächst.
Der fatale Einsatz von Self-Joins ohne Limitierung
Ein weiterer Klassiker ist der Self-Join. Man verbindet die Tabelle mit sich selbst, um Zeilen mit gleichem Inhalt, aber unterschiedlicher ID zu finden. Das sieht auf dem Papier elegant aus. In der Realität erzeugt ein Self-Join auf einer großen Tabelle ohne strikte Filterung ein kartesisches Produkt des Grauens.
Hier ein konkreter Vorher/Nachher-Vergleich aus einem Projekt bei einem Online-Händler:
Vorher: Der Entwickler schrieb einen Join, der jede Zeile mit jeder anderen Zeile verglich, um ähnliche Kundenprofile zu finden. Er filterte lediglich darauf, dass die E-Mail-Adresse gleich sein musste. Die Abfrage lief über 12 Stunden und musste abgebrochen werden, weil sie die gesamte Datenbank für andere Prozesse sperrte. Die Kosten für die Ausfallzeit der Analyse-Plattform beliefen sich auf mehrere tausend Euro an verpassten Marketing-Gelegenheiten.
Nachher: Wir stellten den Prozess um. Zuerst filterten wir in einer temporären Tabelle nur die E-Mail-Adressen heraus, die überhaupt mehr als einmal vorkamen. Erst dann führten wir den Join nur mit diesen bereits identifizierten "Verdächtigen" durch. Die Laufzeit sank von 12 Stunden auf unter 4 Minuten. Warum? Weil die Datenbank statt Millionen von Zeilen nur noch ein paar tausend verarbeiten musste. Das ist der Unterschied zwischen roher Gewalt und Verstand.
Die Gefahr beim Löschen mit Common Table Expressions
Wenn du die Dubletten gefunden hast, willst du sie meistens loswerden. Hier kommen oft Common Table Expressions (CTEs) ins Spiel, kombiniert mit einer ROW_NUMBER() Funktion. Das ist das Werkzeug der Wahl für Profis, aber es ist brandgefährlich. Wenn du deine Partitionierung falsch setzt, löscht du nicht die Kopie, sondern das Original.
Ich habe miterlebt, wie ein Administrator versehentlich die aktuellsten Bestellungen gelöscht hat, weil er die Sortierung innerhalb der OVER-Klausel falsch herum angelegt hatte. Er dachte, er löscht die alten Dubletten, aber er löschte die neuen Datensätze, die gerade erst mühsam vom Vertrieb eingepflegt worden waren. In der Welt der Datenbanken gibt es kein "Rückgängig" ohne ein mühsames Backup-Restore, das die gesamte Firma für Stunden lahmlegt. Bevor du ein DELETE auf Basis deiner Analyse ausführst, mach immer ein SELECT. Schau dir die Zeilen an, die verschwinden sollen. Wenn da auch nur eine Zeile dabei ist, die du behalten willst, stimmt deine Logik nicht.
Die Falle der Zeitstempel
Oft wird versucht, die "ältere" oder "neuere" Dublette anhand eines CreatedAt-Zeitstempels zu identifizieren. Das klingt logisch, ist aber riskant. Was passiert, wenn zwei Datensätze durch einen Import-Fehler exakt die gleiche Millisekunde als Zeitstempel haben? Deine Abfrage wird entweder beide löschen oder beide behalten, je nachdem wie du die Operator-Logik aufgebaut hast. Du brauchst immer einen eindeutigen "Tie-Breaker", meistens die technische ID, um sicherzustellen, dass am Ende genau eine Zeile übrig bleibt. Alles andere ist russisches Roulette mit deinen Geschäftsdaten.
Die SQL Query To Find Duplicates im Kontext von DSGVO und Compliance
In Deutschland und Europa ist das Thema Dubletten nicht nur ein technisches Ärgernis, sondern ein rechtliches Minenfeld. Wenn du Kundendaten bereinigst, musst du sicherstellen, dass du nicht versehentlich Sperrvermerke oder Werbewidersprüche löschst.
In meiner Praxis kam es vor, dass ein Unternehmen Dubletten bereinigte und dabei den Datensatz behielt, der keine Information über den Werbe-Opt-out des Kunden enthielt. Das Ergebnis war eine Abmahnwelle, weil Kunden kontaktiert wurden, die das explizit untersagt hatten. Die technische Bereinigung muss also immer die fachliche Hierarchie respektieren. Welcher Datensatz ist die "Golden Record"? Welcher hat die höchste Qualität? Das kann keine SQL-Abfrage der Welt allein entscheiden. Da muss ein Fachbereich mit am Tisch sitzen und die Regeln definieren. Wer das ignoriert, spart vielleicht heute Zeit bei der Datenbankpflege, zahlt aber morgen das Dreifache an Anwaltsgebühren.
Warum reguläre Ausdrücke oft mehr schaden als nützen
Manchmal versuchen Leute, besonders schlau zu sein und nutzen Regular Expressions (RegEx) innerhalb ihrer SQL-Statements, um Dubletten zu finden, die fast gleich klingen. Das klappt in kleinen Test-Umgebungen wunderbar. Sobald du das auf eine Produktionsdatenbank mit Millionen Einträgen loslässt, bricht die CPU-Last durch die Decke. SQL-Server sind für Mengenoperationen optimiert, nicht für komplexe Textmuster-Analysen in jeder einzelnen Zeile.
Wenn du wirklich unsaubere Daten hast, die nicht exakt übereinstimmen, ist der Weg über SQL allein meist der falsche. Dann brauchst du Tools für "Fuzzy Matching" oder du musst die Daten vorher normalisieren. Das bedeutet: Alle Leerzeichen raus, alles in Großbuchstaben wandeln, Sonderzeichen entfernen und das Ergebnis in einer Hilfsspalte speichern. Erst auf dieser bereinigten Hilfsspalte lässt du dann deine Suche laufen. Das ist ein Schritt mehr Arbeit, rettet dir aber die Performance deines Servers.
Realitätscheck: Was es wirklich braucht
Vergiss die Vorstellung, dass du ein fertiges Skript aus dem Internet kopierst und danach eine saubere Datenbank hast. Das wird nicht passieren. Datenbereinigung ist ein schmutziger, iterativer Prozess. Wer behauptet, er könne mit einer einzigen cleveren Abfrage alle Probleme lösen, hat noch nie an einer wirklich großen, gewachsenen Datenbank gearbeitet.
Es braucht Zeit. In einem typischen Projekt verbringen wir 80 % der Zeit mit der Analyse und nur 20 % mit dem eigentlichen Schreiben der Abfrage. Du musst die Daten verstehen. Du musst wissen, warum die Dubletten überhaupt entstehen. Wenn du das Loch im Eimer nicht flickst, kannst du so viel Wasser rausschöpfen, wie du willst — morgen ist der Eimer wieder voll. Das bedeutet: Schau dir die Applikationslogik an, die die Daten schreibt. Warum erlaubt sie Doppeleinträge? Gibt es keine Unique Constraints?
Erfolg in diesem Bereich bedeutet nicht, ein SQL-Guru zu sein. Es bedeutet, vorsichtig zu sein. Es bedeutet, Backups zu haben, die auch wirklich funktionieren. Und es bedeutet, die Arroganz abzulegen, zu glauben, man könne die Komplexität von menschlich eingegebenen Daten mit drei Zeilen Code perfekt beherrschen. Wenn du das nächste Mal eine Bereinigung planst, rechne mit dem Doppelten an Zeitaufwand und stell sicher, dass dein Restore-Plan getestet ist. Alles andere ist verantwortungslos gegenüber dem Unternehmen und deiner eigenen Karriere. Es ist harte Arbeit, es ist oft langweilig, und es gibt keine Abkürzung, die nicht irgendwo ein Risiko verbirgt.



