Wer schon mal versucht hat, einen bestimmten Datensatz in einer Tabelle mit Millionen von Einträgen zu finden, ohne ein eindeutiges Merkmal zu besitzen, kennt den Frust. Es ist wie die Suche nach einer Nadel im Heuhaufen, während jemand ständig neuen Stahl in den Haufen wirft. Wenn du eine neue Struktur aufsetzt, ist der Befehl Sql Create Table Primary Key dein wichtigstes Werkzeug für Ordnung. Ohne diesen Anker schwimmen deine Daten ziellos umher. Du riskierst Dubletten, die dein System lahmlegen. Ich habe Datenbanken gesehen, in denen Nutzerprofile dreifach existierten, nur weil die Entwickler am Anfang zu faul für eine saubere Identifikation waren. Das kostet später Tage an Korrekturarbeit. Wer professionell mit Daten arbeitet, akzeptiert keine Kompromisse bei der Eindeutigkeit.
Die harte Wahrheit über Identität in Datenbanken
In der Welt von SQL dreht sich alles um Relationen. Aber eine Relation funktioniert nur, wenn jede Zeile eine Persönlichkeit hat. Stell dir vor, du hast eine Liste von Kunden. Zehn davon heißen Thomas Müller. Wie unterscheidest du den Thomas aus Berlin von dem aus München, wenn sie beide am gleichen Tag Geburtstag haben? Hier kommt die technische Identität ins Spiel. Ein Primärschlüssel garantiert, dass jeder Eintrag eineindeutig ist. Er darf niemals den Wert NULL annehmen. Das ist eine eiserne Regel. Wenn ein Feld leer sein darf, taugt es nicht als Schlüssel.
Warum einfache Namen niemals ausreichen
Anfänger machen oft den Fehler, natürliche Daten als Schlüssel zu wählen. Das klingt logisch. Jeder Mensch hat eine Steuernummer oder eine Sozialversicherungsnummer. Aber was passiert, wenn sich ein Wert ändert? Oder wenn bei der Eingabe ein Tippfehler passiert? Ein Primärschlüssel sollte im Idealfall "starr" sein. Er ändert sich nie. Deshalb greifen Profis fast immer zu künstlichen Schlüsseln. Eine fortlaufende Nummer ist simpel. Sie ist schnell. Sie belegt wenig Speicherplatz. Das System muss nicht mühsam lange Textketten vergleichen, um eine Verknüpfung zu finden.
Die Performance-Falle bei fehlenden Schlüsseln
Ein fehlender Primärschlüssel ist ein Performance-Killer. Ohne ihn muss die Datenbank bei jeder Abfrage einen sogenannten Full Table Scan machen. Das bedeutet, sie liest jeden einzelnen Datensatz von der Festplatte, um zu prüfen, ob er passt. Bei 100 Zeilen merkst du das nicht. Bei 100 Millionen Zeilen glüht der Server. Der Primärschlüssel erstellt automatisch einen Index. Das ist wie ein Inhaltsverzeichnis in einem dicken Buch. Die Datenbank springt direkt zur richtigen Seite. Das spart Rechenzeit und schont die Hardware.
Der richtige Weg für Sql Create Table Primary Key in der Praxis
Es gibt verschiedene Arten, wie du diese Struktur anlegst. Meistens definierst du den Schlüssel direkt beim Erstellen der Tabelle. Das ist sauberer Code. Du legst fest, welche Spalte die Führung übernimmt. In der Regel ist das die erste Spalte im Skript.
Die Syntax für einzelne Spalten
Man schreibt den Namen der Spalte, den Datentyp und dann die magischen Worte. In den meisten Dialekten wie PostgreSQL oder MySQL sieht das fast identisch aus. Hier ein Beispiel für eine Nutzertabelle. Die ID bekommt den Typ INT. Dahinter setzen wir die Anweisung für den Primärschlüssel. Das System weiß nun: Diese Zahl darf nur einmal vorkommen. Versucht jemand, die gleiche Zahl doppelt einzufügen, blockt die Datenbank das ab. Das ist eine Schutzfunktion. Sie bewahrt dich vor deinen eigenen Fehlern oder vor Bugs in deiner Applikation.
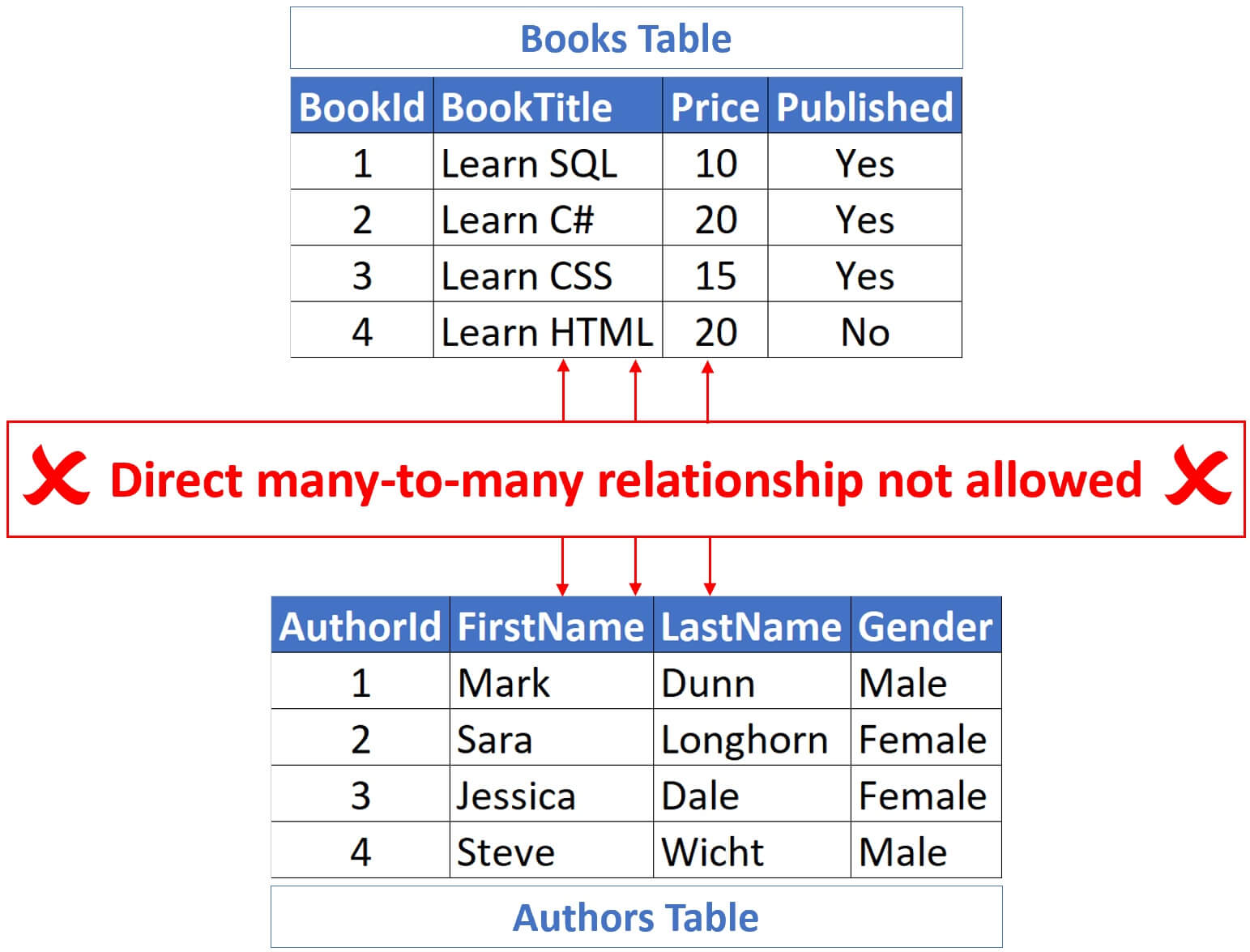
Zusammengesetzte Schlüssel für komplexe Fälle
Manchmal reicht eine Spalte nicht aus. Denk an eine Tabelle, die Kinoplätze speichert. Ein Sitz wird durch die Reihe und die Nummer definiert. Reihe 5, Platz 12. Erst die Kombination macht den Platz einzigartig. In solchen Fällen definierst du einen zusammengesetzten Primärschlüssel am Ende deiner Anweisung. Das ist oft in Verknüpfungstabellen nötig, die zwei andere Tabellen miteinander verbinden. Es erfordert etwas mehr Planung, ist aber extrem mächtig für die Datenintegrität.
Warum UUIDs oft besser sind als einfache Zahlen
In modernen verteilten Systemen stoßen einfache Ganzzahlen an ihre Grenzen. Wenn du zwei Datenbanken in verschiedenen Rechenzentren hast, die beide IDs hochzählen, kriegst du beim Zusammenführen der Daten ein Problem. Beide haben eine ID 1. Beide haben eine ID 2. Der Konflikt ist vorprogrammiert. Hier glänzen UUIDs (Universally Unique Identifiers). Das sind lange Ketten aus Zahlen und Buchstaben. Die Wahrscheinlichkeit, dass weltweit zwei gleiche UUIDs generiert werden, ist praktisch null.
Ehrlicherweise haben UUIDs auch Nachteile. Sie sind groß. Sie brauchen mehr Platz auf der Platte. Sie sind für Menschen schwer zu lesen. Wenn du nur eine kleine interne Webseite baust, bleib bei normalen Zahlen. Wenn du aber für die Cloud skalierst, schau dir UUIDs genau an. Microsoft bietet hierfür oft spezifische Datentypen an, die man in der offiziellen Dokumentation von Microsoft SQL Server nachschlagen kann. Es kommt immer auf den Kontext an.
Häufige Fehler beim Design von Tabellen
Ich sehe immer wieder die gleichen Patzer. Der Klassiker ist der "sprechende Schlüssel". Leute nutzen die E-Mail-Adresse als Primärschlüssel. Das klingt erst mal schlau. Jeder hat eine eigene E-Mail. Aber was ist, wenn der Nutzer seine Adresse ändert? Dann musst du diesen Schlüssel in allen verknüpften Tabellen ändern. Das ist ein Albtraum für die Konsistenz. Ändert man es an einer Stelle nicht, entstehen Datenleichen. Man nennt das verwaiste Datensätze. Ein Primärschlüssel sollte keine Bedeutung haben. Er ist nur ein technisches Hilfsmittel.
Datentypen und ihre Tücken
Wähle den kleinstmöglichen Datentyp. Wenn du weißt, dass du nie mehr als 200 Einträge hast, brauchst du kein BIGINT. Das verschwendet nur RAM. Aber sei nicht zu geizig. Ein normaler Integer geht bis etwa zwei Milliarden. Das klingt viel. Für ein soziales Netzwerk mit Millionen Posts pro Tag ist das nach einem Jahr zu wenig. Der Überlauf eines Integers hat schon ganze Systeme zum Absturz gebracht. Plane für das Wachstum. Schau dir an, wie große Open-Source-Projekte ihre Schemas strukturieren. Die PostgreSQL-Dokumentation gibt exzellente Einblicke in die verschiedenen Constraint-Typen und deren Auswirkungen.
Die Angst vor der Migration
Viele trauen sich nicht, einen Primärschlüssel nachträglich einzuführen. Das ist verständlich. Es ist riskant. Wenn du bereits Dubletten in der Tabelle hast, verweigert die Datenbank den Befehl. Du musst erst aufräumen. Du musst die doppelten Zeilen identifizieren und löschen. Erst dann kannst du die Integritätsregel erzwingen. Mein Rat: Mach es sofort beim ersten Entwurf. Ein späteres "Fixing" kostet das Zehnfache an Zeit.
Sql Create Table Primary Key in verschiedenen Systemen
Die Welt der Datenbanken ist groß. Es gibt MySQL, MariaDB, Oracle und SQLite. Die Grundlagen sind überall gleich, aber die Details unterscheiden sich. Manche Systeme nutzen das Schlüsselwort AUTO_INCREMENT, andere setzen auf SEQUENCES.
Die feinen Unterschiede bei MySQL und MariaDB
In der Welt von MySQL ist AUTO_INCREMENT der Standardweg. Du definierst die Spalte und das System zählt von alleine hoch. Du musst dich beim Einfügen neuer Daten nicht um die ID kümmern. Das übernimmt die Engine für dich. Es ist bequem. Es ist sicher. MariaDB folgt diesem Pfad fast identisch. Diese Systeme sind für das Web optimiert und verzeihen viel, solange du die Grundregeln der Indizierung beachtest.
Enterprise-Lösungen wie Oracle
Bei Oracle war es lange Zeit üblich, Sequenzen und Trigger zu nutzen, um einen Primärschlüssel automatisch zu füllen. Das wirkt für Einsteiger sperrig. Es bietet aber mehr Kontrolle. Du kannst eine Sequenz für mehrere Tabellen nutzen oder Sprünge einbauen. Moderne Versionen haben das vereinfacht, aber die alte Logik steckt noch in vielen Banksystemen. Dort ist Stabilität wichtiger als Bequemlichkeit. Wenn du dort mit Daten hantierst, merkst du schnell, dass jede Entscheidung dreimal geprüft wird. Die Integrität steht über allem.
Praktische Tipps für saubere Tabellenstrukturen
Ein guter Entwickler denkt nicht nur an den Code von heute. Er denkt an den Kollegen, der den Code in zwei Jahren warten muss. Benenne deine Primärschlüsselspalten konsistent. Entweder nennst du sie in jeder Tabelle einfach "id" oder du nutzt den Tabellennamen als Präfix, zum Beispiel "user_id". Ich bevorzuge Letzteres. Wenn du später Abfragen über mehrere Tabellen schreibst, weißt du sofort, welche ID zu wem gehört. Das vermeidet Verwirrung bei Joins.
- Nutze immer einen Primärschlüssel, ohne Ausnahmen.
- Verwende technische IDs statt natürlicher Daten.
- Achte auf den passenden Datentyp für die erwartete Datenmenge.
- Dokumentiere, warum du dich für einen bestimmten Schlüsseltyp entschieden hast.
Sicherheit ist ein weiteres Thema. Primärschlüssel in URLs zu zeigen, kann gefährlich sein. Wenn deine Nutzer-ID 123 in der Browserzeile steht, probiert jemand vielleicht einfach 124 aus. Das nennt man Insecure Direct Object Reference (IDOR). Hier sind UUIDs wieder im Vorteil, weil sie nicht erratbar sind. Man kann sie nicht einfach hochzählen. Wer Sicherheit ernst nimmt, trennt die interne Datenbank-ID von der externen Referenz-ID.
Die Rolle von Primärschlüsseln bei der Datenanalyse
Wenn Datenanalysten Berichte erstellen, verlassen sie sich blind auf deine Schlüssel. Sie verknüpfen Tabellen, um Umsätze pro Region oder Klickraten zu berechnen. Wenn dein Primärschlüssel schwächelt, sind alle Berichte falsch. Ein falscher Join wegen fehlender Eindeutigkeit kann Zahlen künstlich aufblähen. Stell dir vor, ein Verkauf wird doppelt gezählt, weil die Verknüpfung nicht sauber war. Das Management trifft Entscheidungen auf Basis falscher Daten. Das ist der Super-GAU für jeden Datenexperten.
Normalisierung ist kein Selbstzweck
Man lernt in der Uni oft die verschiedenen Normalformen. Die erste Normalform verlangt zwingend einen Primärschlüssel. Aber in der Realität geht es um mehr als nur Theorie. Es geht um Wartbarkeit. Eine gut strukturierte Datenbank ist selbsterklärend. Wenn ich in ein Schema schaue und sofort sehe, wie die Tabellen über Primär- und Fremdschlüssel zusammenhängen, brauche ich kaum Dokumentation. Der Code spricht für sich selbst. Das spart Einarbeitungszeit für neue Teammitglieder.
Indizes jenseits des Primärschlüssels
Der Primärschlüssel ist der wichtigste Index, aber oft nicht der einzige. Wenn du oft nach dem Namen suchst, brauchst du dort auch einen Index. Aber Vorsicht: Zu viele Indizes machen Schreibvorgänge langsam. Jedes Mal, wenn du eine Zeile einfügst, muss die Datenbank alle Inhaltsverzeichnisse aktualisieren. Es ist eine Gratwanderung. Der Primärschlüssel ist jedoch der eine Index, bei dem du niemals sparen darfst. Er ist das Fundament. Alles andere ist optionaler Luxus für die Geschwindigkeit.
Strategien für die Zukunft deiner Daten
Die Welt der Daten ändert sich schnell. NoSQL-Datenbanken wie MongoDB haben eine Zeit lang versucht, das Konzept von festen Schemen über Bord zu werfen. Aber selbst dort gibt es fast immer eine eindeutige ID pro Dokument. Warum? Weil Identität eine universelle Notwendigkeit ist. Ohne Identität gibt es keine Beziehung. Ohne Beziehung gibt es keine Information, sondern nur Rauschen.
Wenn du heute deine Tabellen planst, denk an die Cloud. Denk an Skalierbarkeit. Vielleicht musst du deine Daten irgendwann aufteilen (Sharding). Dabei spielt die Wahl deines Schlüssels eine zentrale Rolle. Ein guter Schlüssel erlaubt es, Daten logisch zu gruppieren. Ein schlechter Schlüssel zwingt dich zu komplexen Umwegen. Wer von Anfang an sauber arbeitet, hat später weniger schlaflose Nächte. Es ist wie beim Hausbau. Wenn das Fundament schief ist, nützt auch die schönste Fassade nichts.
Konkrete Schritte für dein nächstes Projekt
Genug der Theorie. Wenn du das nächste Mal vor einer leeren Konsole sitzt, geh methodisch vor. Überstürze nichts. Ein schlecht gewähltes Schema ist schwerer zu korrigieren als ein fehlerhafter Algorithmus.
- Analysiere deine Datenobjekte genau. Was macht ein Objekt wirklich einzigartig?
- Entscheide dich für einen ID-Typ. Für kleine Projekte reicht ein Integer, für große Systeme nimm UUIDs.
- Schreibe dein Skript sauber nieder. Achte auf Lesbarkeit.
- Teste die Eindeutigkeit. Versuche absichtlich, Dubletten einzufügen. Die Datenbank muss eine Fehlermeldung werfen.
- Überprüfe die Abfragegeschwindigkeit mit dem Befehl EXPLAIN. Schau nach, ob der Index des Primärschlüssels genutzt wird.
- Erstelle ein Backup deines Schemas.
Datenbankdesign ist ein Handwerk. Es erfordert Erfahrung und den Blick für Details. Lass dich nicht von schnellen Lösungen verführen, die später Probleme machen. Ein sauberer Primärschlüssel ist das beste Geschenk, das du deinem zukünftigen Ich machen kannst. Du wirst es danken, wenn du in zwei Jahren eine komplexe Abfrage schreibst und alles reibungslos funktioniert. Vertrau auf die bewährten Methoden der relationalen Welt. Sie haben sich über Jahrzehnte bewährt, weil sie funktionieren. Viel Erfolg beim Aufbau deiner nächsten stabilen Datenbankumgebung. Geh jetzt an die Arbeit und setz die Theorie in die Tat um. Deine Daten verdienen ein sicheres Zuhause.



