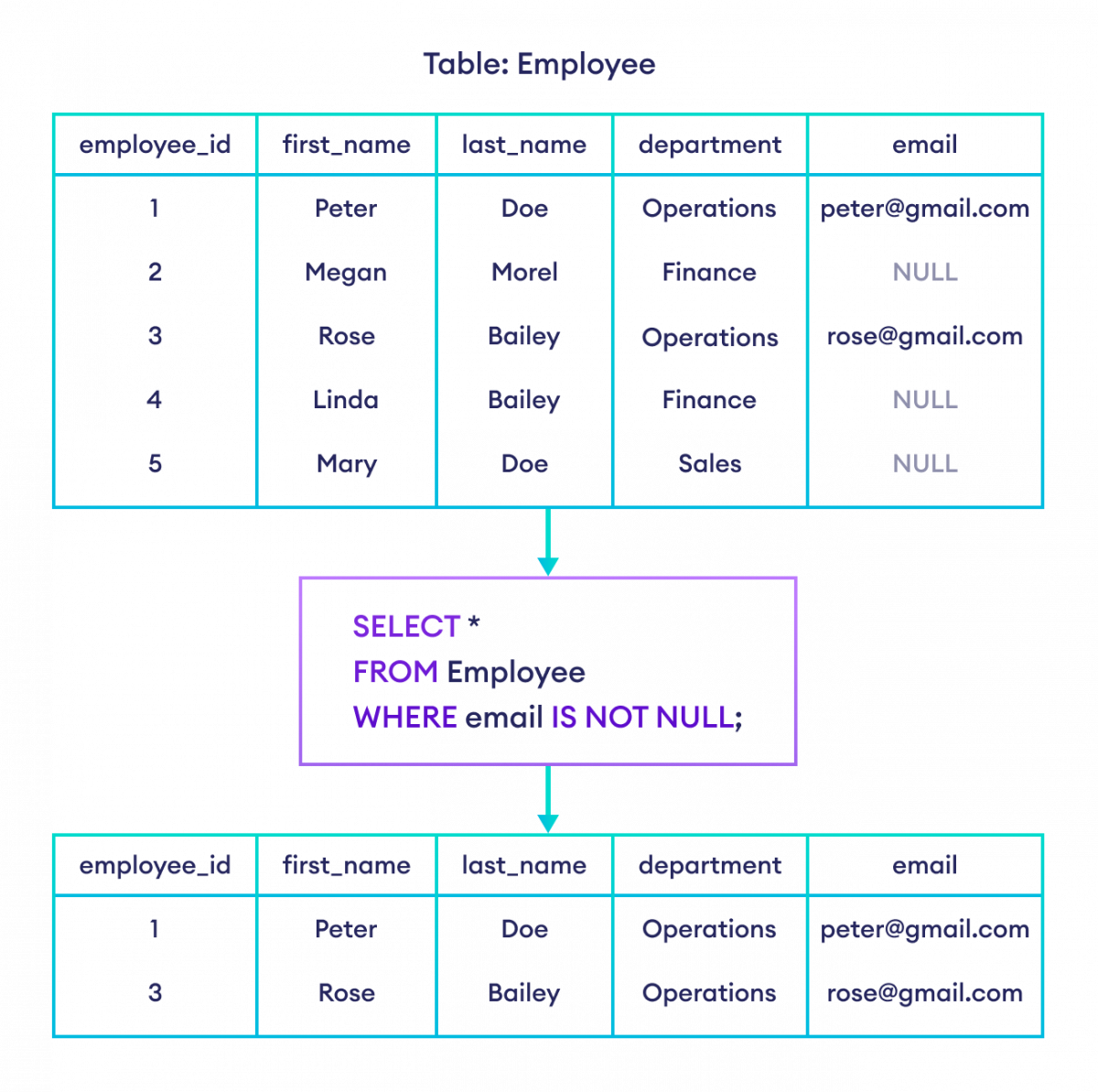
Jeder Entwickler kennt diesen Moment am späten Nachmittag, wenn eine eigentlich simple Abfrage die Datenbank in die Knie zwingt. Du willst einfach nur alle Kunden finden, die im letzten Monat keine Bestellung aufgegeben haben. Der erste Impuls ist fast immer der Griff zu SQL Where Is Not In, doch genau hier beginnt oft das Drama mit der Performance und den Null-Werten. Wer blindlings Listen ausschließt, ohne die Logik dahinter zu verstehen, baut sich eine Zeitbombe in den Code. In der Praxis ist SQL nicht nur eine Sprache für Abfragen, sondern ein System, das strikten mathematischen Regeln folgt. Wenn diese Regeln missachtet werden, liefert die Datenbank entweder falsche Ergebnisse oder braucht Minuten für eine Aufgabe, die Millisekunden dauern sollte.
Die Tücke mit Null-Werten bei SQL Where Is Not In
Die Arbeit mit relationalen Datenbanken erfordert ein tiefes Verständnis der dreiwertigen Logik. Es gibt Wahr, Falsch und Unbekannt. Wenn du eine Liste von Werten hast und einer dieser Werte NULL ist, wird die gesamte Bedingung für den Ausschluss unvorhersehbar. Das ist kein Bug, das ist der SQL-Standard. Viele Einsteiger denken, dass ein Vergleich gegen eine Liste einfach alle unpassenden Treffer ignoriert. Das stimmt aber nicht. Sobald in deiner Unterabfrage ein einziger Datensatz mit einem NULL-Wert auftaucht, gibt die gesamte Bedingung kein Ergebnis mehr zurück. Das liegt daran, dass SQL nicht wissen kann, ob der gesuchte Wert dem "unbekannten" Wert entspricht oder nicht.
Das logische Problem im Detail
Stell dir vor, du hast eine Tabelle mit Filialen und eine mit Umsätzen. Du suchst Filialen ohne Umsatz. Wenn in der Umsatzliste eine Zeile existiert, bei der die Filial-ID nicht eingetragen wurde, bricht die Logik zusammen. Mathematisch gesehen versucht die Datenbank zu prüfen, ob die aktuelle ID ungleich dem ersten Element, ungleich dem zweiten Element und so weiter ist. Wenn sie beim Vergleich mit NULL ankommt, ist das Ergebnis "Unbekannt". Da eine WHERE-Bedingung nur Zeilen liefert, bei denen das Ergebnis eindeutig "Wahr" ist, wird die Zeile verworfen.
Warum die Performance oft leidet
Neben der Logik ist die Geschwindigkeit ein massives Argument gegen diese Methode bei großen Datenmengen. Die Datenbank muss bei dieser Art der Filterung oft die gesamte Liste im Speicher halten oder für jeden Datensatz der Haupttabelle einen kompletten Scan der Untertabelle durchführen. Das skaliert schrecklich. Bei ein paar hundert Zeilen merkst du nichts. Wenn du aber bei Millionen von Datensätzen arbeitest, merkst du schnell, wie die CPU-Last nach oben schnellt. Ein erfahrener Administrator wird dir sofort raten, die Abfrage umzubauen.
Bessere Alternativen zu SQL Where Is Not In
Es gibt fast immer einen effizienteren Weg, um Daten auszuschließen. Profis nutzen meistens NOT EXISTS oder einen LEFT JOIN in Kombination mit einer IS NULL Prüfung. Diese Ansätze sind nicht nur sicherer im Umgang mit fehlenden Daten, sondern lassen dem Query-Optimizer der Datenbank auch viel mehr Spielraum für Optimierungen. Ein LEFT JOIN zum Beispiel erlaubt es der Datenbank, Indizes viel effektiver zu nutzen. Du verknüpfst zwei Tabellen und suchst dann gezielt nach den Lücken, die beim Zusammenfügen entstehen. Das ist sauber und nachvollziehbar.
Die Überlegenheit von NOT EXISTS
In den meisten modernen Systemen wie PostgreSQL oder Microsoft SQL Server ist NOT EXISTS die bevorzugte Wahl. Der Grund ist simpel: Die Datenbank hört auf zu suchen, sobald sie den ersten Treffer findet. Sie muss nicht die komplette Liste der auszuschließenden IDs validieren. Das spart wertvolle I/O-Zyklen. Außerdem ist die Syntax für viele lesbarer, da sie die Beziehung zwischen den Tabellen explizit macht. Du sagst der Datenbank: "Gib mir alle Kunden, für die keine Zeile in der Bestellungstabelle existiert, die zu diesem Kunden gehört."
Der klassische Join-Trick
Ein LEFT JOIN ist oft das Schweizer Taschenmesser der SQL-Optimierung. Du nimmst alle Datensätze der linken Tabelle und versuchst, die rechte Tabelle dranzuhängen. Wo kein Gegenstück existiert, füllt SQL die Spalten mit NULL auf. Wenn du danach filterst, hast du genau das Ergebnis, das du suchst. Dieser Ansatz ist besonders nützlich, wenn du ohnehin Daten aus der zweiten Tabelle anzeigen willst, falls sie vorhanden sind. Es ist ein robuster Weg, der in fast jeder SQL-Dialekt-Umgebung gleich gut funktioniert.
Reale Szenarien aus der Praxis
Ich habe Projekte gesehen, in denen Berichte über Nacht liefen, nur weil jemand SQL Where Is Not In für den Ausschluss von Stornierungen verwendet hat. Nachdem wir die Abfrage auf ein NOT EXISTS Konstrukt umgestellt hatten, sank die Laufzeit von sechs Stunden auf unter zehn Minuten. Das zeigt, dass kleine Syntax-Entscheidungen massive Auswirkungen auf die Infrastrukturkosten haben können. Besonders bei Cloud-Datenbanken, wo du pro Rechenzeit bezahlst, kostet schlechter Code echtes Geld.
Fehlersuche in der Warenwirtschaft
Nehmen wir an, du arbeitest an einem System für ein großes Lager. Du musst alle Artikel finden, die noch nie inventarisiert wurden. Wenn du hier die falsche Filtertechnik wählst und deine Inventurtabelle Millionen von Einträgen hat, wird deine Anwendung hängen bleiben. Ein Index auf der Artikelnummer hilft dir nur bedingt, wenn die Abfragestruktur die Datenbank zwingt, temporäre Tabellen auf der Festplatte zu erstellen. In solchen Fällen ist es ratsam, sich die Ausführungspläne genau anzusehen. Die Datenbank verrät dir meistens selbst, wo sie die meiste Zeit verliert.
Datenbereinigung und Migration
Oft tritt das Problem bei der Datenmigration auf. Du willst Datensätze von System A nach System B schieben, aber nur die, die noch nicht da sind. Hier ist Präzision gefragt. Ein falscher Ausschluss führt dazu, dass Daten fehlen. Ich verlasse mich hier nie auf einfache Listenvergleiche. Stattdessen nutze ich temporäre Tabellen und setze explizite Indizes, bevor ich den finalen Abgleich mache. Das gibt mir die Kontrolle und verhindert Überraschungen durch inkonsistente Quelldaten.
Optimierung der Datenbankstruktur
Guter Code beginnt bei der Tabellenstruktur. Wenn du Spalten hast, die keine NULL-Werte enthalten dürfen, dann markiere sie auch so mit einem NOT NULL Constraint. Das hilft nicht nur der Datenintegrität, sondern auch dem Optimizer. Wenn die Datenbank weiß, dass ein Wert niemals NULL sein kann, kann sie bestimmte Sicherheitsprüfungen überspringen. Das macht die Abfragen schneller. Viele unterschätzen die Macht von ordentlich gepflegten Metadaten. Ein gut gesetzter Index auf einer Fremdschlüsselspalte ist oft die halbe Miete.
Index-Strategien für Ausschlüsse
Ausschlüsse sind für Indizes grundsätzlich schwieriger als direkte Treffer. Ein Index ist darauf optimiert, etwas zu finden, nicht etwas nicht zu finden. Trotzdem helfen sie massiv. Bei einem NOT EXISTS wird der Index genutzt, um die Existenz schnell zu prüfen. Ohne Index müsste die Datenbank jedes Mal einen Full Table Scan machen. Das ist bei großen Tabellen der Performance-Killer Nummer eins. Achte darauf, dass deine Join-Partner immer den gleichen Datentyp haben. Ein Vergleich zwischen einer Ganzzahl und einem Textfeld zwingt die Datenbank zur Konvertierung während der Laufzeit, was jeden Index nutzlos macht.
Die Rolle von Statistiken
Datenbanken führen Statistiken darüber, wie die Daten verteilt sind. Wenn die Statistik veraltet ist, wählt der Optimizer vielleicht einen schlechten Weg für deinen Ausschluss. Es lohnt sich, bei Performance-Problemen die Statistiken manuell zu aktualisieren. Besonders nach großen Löschaktionen oder Massen-Imports ist das zwingend erforderlich. Ein moderner SQL-Server wie der von Microsoft bietet Werkzeuge an, um genau solche Engpässe zu identifizieren.
Häufige Fehler vermeiden
Ein Fehler, den ich immer wieder sehe, ist das Verschachteln von zu vielen Unterabfragen. Jede Ebene macht den Code schwerer lesbar und für die Datenbank schwerer zu optimieren. Versuche, deine Abfragen flach zu halten. Common Table Expressions (CTEs) können helfen, die Logik zu strukturieren, ohne die Performance zu opfern. Sie sind oft übersichtlicher als tief eingerückte Subselects. Wer sauberen Code schreibt, produziert meistens auch effizienteren Code.
Die Verwechslung mit NOT IN
Manche denken, es gäbe keinen Unterschied zwischen den verschiedenen negierten Filtern. Doch die subtilen Abweichungen in der Behandlung von Duplikaten und Leeren Mengen können verheerend sein. Wenn die Liste in deiner Bedingung leer ist, verhält sich das System anders, als wenn sie Werte enthält. Teste deine Abfragen immer mit Randfällen. Was passiert, wenn die Zieltabelle leer ist? Was passiert, wenn sie nur NULL-Werte enthält? Nur wer diese Fragen beantwortet, schreibt produktionsreifen Code.
Die Bedeutung von Code-Reviews
Lass deinen SQL-Code von anderen prüfen. Oft sieht ein Kollege sofort, dass ein Join an dieser Stelle besser wäre. In vielen Teams herrscht die Meinung vor, dass SQL "schon irgendwie laufen wird". Das ist eine gefährliche Einstellung. Datenbankabfragen sind oft der Flaschenhals moderner Webanwendungen. Ein Blick in die Dokumentation von PostgreSQL zeigt oft alternative Funktionen, die spezifisch für bestimmte Probleme entwickelt wurden. Nutze dieses Wissen.
Fortgeschrittene Techniken
Wenn du wirklich an die Grenzen stößt, gibt es noch andere Wege. Manchmal ist es schneller, zwei Mengen mit dem EXCEPT-Operator voneinander abzuziehen. Das ist Mengenlehre pur und wird von vielen Datenbanken sehr effizient umgesetzt. Es ist oft intuitiver zu schreiben: "Gib mir alle IDs aus Tabelle A außer denen, die in Tabelle B vorkommen". Das liest sich fast wie natürliches Deutsch und vermeidet die typischen Fallstricke der WHERE-Klauseln.
Partitionierung nutzen
Bei extrem großen Tabellen hilft oft nur noch die Partitionierung. Wenn du deine Daten nach Datum oder Region aufteilst, muss die Datenbank beim Ausschluss nur noch in den relevanten Partitionen suchen. Das reduziert die Datenmenge, die gescannt werden muss, dramatisch. Das erfordert natürlich eine vorausschauende Planung der Datenbankarchitektur. Wer erst optimiert, wenn die Festplatte glüht, hat meistens schon zu lange gewartet.
Materialisierte Sichten
Manchmal ist es sinnvoll, das Ergebnis eines komplexen Ausschlusses in einer materialisierten Sicht zwischenzuspeichern. Das bietet sich an, wenn die Daten nicht in Echtzeit aktuell sein müssen. Du berechnest die Liste der "fehlenden" Einträge einmal pro Stunde und greifst dann blitzschnell auf dieses fertige Ergebnis zu. Das entlastet die Live-Systeme und sorgt für konstante Antwortzeiten. Das ist besonders bei Dashboards oder Analysetools eine gängige Praxis.
Warum SQL-Standards wichtig sind
SQL ist über Jahrzehnte gewachsen. Die Regeln für Vergleiche und Logik sind nicht willkürlich, sondern basieren auf mathematischen Grundlagen der Mengenlehre. Wer versucht, diese Regeln zu umgehen oder sie ignoriert, wird früher oder später scheitern. Es ist wichtig, den offiziellen Standard zu kennen, auch wenn jeder Hersteller seine eigenen kleinen Erweiterungen kocht. Die Kernlogik bleibt gleich. Konsistenz ist hier wichtiger als Bequemlichkeit.
Portabilität des Codes
Wenn du dich an saubere Standards hältst, ist es viel einfacher, von einer Datenbank zur anderen zu wechseln. Vielleicht zieht dein Unternehmen morgen von einem lokalen Server in die Cloud um. Wenn dein Code voller herstellerspezifischer Hacks ist, wird die Migration zum Albtraum. Sauberes SQL, das auf bewährten Mustern basiert, läuft fast überall ohne große Anpassungen. Das spart Zeit und Nerven.
Werkzeuge zur Analyse
Nutze Tools wie EXPLAIN ANALYZE, um zu sehen, was unter der Haube passiert. Diese Befehle zeigen dir den tatsächlichen Ausführungsplan und die Kosten für jeden Schritt. Du siehst sofort, ob ein Index Scan oder ein Sequential Scan durchgeführt wird. Es ist faszinierend zu sehen, wie eine kleine Änderung in der Syntax den gesamten Plan umwirft. Wer diese Werkzeuge beherrscht, spielt in einer ganz anderen Liga als jemand, der nur raten kann.
Praktische nächste Schritte
Wenn du das nächste Mal vor der Aufgabe stehst, Daten auszuschließen, halte kurz inne. Prüfe zuerst, ob deine Spalten NULL-Werte enthalten können. Wenn ja, ist Vorsicht geboten. Überlege, ob ein NOT EXISTS nicht die sicherere und schnellere Variante ist. Schreibe die Abfrage testweise auf beide Arten und vergleiche die Ausführungszeit mit echten Daten. Es ist auch hilfreich, sich die Zeilenanzahl der beteiligten Tabellen anzusehen. Was bei 1000 Zeilen funktioniert, kann bei einer Million kläglich scheitern.
Deine Checkliste für die nächste Abfrage
- Prüfe die Tabellendefinition auf NULL-Constraints.
- Überlege, ob ein LEFT JOIN mit IS NULL Filter logisch das gleiche liefert.
- Teste die Performance mit EXPLAIN bei realistischen Datenmengen.
- Stelle sicher, dass Indizes auf den Join-Spalten liegen.
- Dokumentiere, warum du dich für eine bestimmte Methode entschieden hast, damit deine Kollegen es später verstehen.
Langfristige Strategie
Entwickle ein Gefühl für die Datenverteilung in deiner Anwendung. Wer seine Daten kennt, schreibt besseres SQL. Es geht nicht nur darum, dass die Abfrage funktioniert. Sie muss stabil, wartbar und schnell sein. SQL ist ein mächtiges Werkzeug, aber wie bei jedem Werkzeug kommt es auf die Handhabung an. Ein erfahrener Handwerker pflegt seine Werkzeuge und nutzt sie mit Bedacht. Das Gleiche gilt für Datenbankentwickler. Bilde dich ständig weiter und schau dir an, wie große Plattformen ihre Datenprobleme lösen. Es gibt immer etwas Neues zu lernen, besonders in der Welt der Daten.



