Stell dir vor, du sitzt im Auto, fluchst über den Berufsverkehr in München oder Hamburg und willst einfach nur eine Nachricht verschicken, ohne gegen einen Pfeiler zu krachen. Du sprichst, dein Handy schreibt, und eine Stimme liest dir die Antwort vor. Das wirkt heute banal. Aber hinter dieser Alltäglichkeit verbirgt sich ein technologisches Monstrum, das unsere Art zu kommunizieren radikal verändert hat. Viele Leute stellen sich die Frage: Speech Recognition and Synthesis Was Ist Das eigentlich im Detail? Im Kern geht es darum, die Barriere zwischen menschlicher Sprache und binärem Computercode einzureißen. Es ist die Kunst, Schallwellen in Text zu verwandeln und kalten Text in eine Stimme zu gießen, die nicht mehr nach einem blechernen Roboter aus den 80ern klingt.
Die Magie hinter dem Zuhören und Sprechen
Wer verstehen will, wie Computer uns begreifen, muss sich von der Vorstellung lösen, dass die Maschine Wörter "hört". Ein Computer hört nichts. Er misst Spannungsveränderungen. Bei der Spracherkennung zerlegt das System deine Stimme in winzige Fragmente. Diese Schnipsel werden mit riesigen Datenbanken abgeglichen. Früher passierte das mit starren Regeln. Das war grauenhaft. Man musste jedes Wort einzeln und deutlich aussprechen. Wer sächselt oder einen bayerischen Akzent hat, flog sofort raus. Heute regieren neuronale Netze. Diese Systeme lernen durch schiere Masse. Sie fressen Millionen Stunden an Audiomaterial, um Muster zu erkennen. Kürzlich viel diskutiert: Das Flüstern der fernen Giganten oder was A39 uns verschweigt.
Die Kehrseite ist die Synthese. Hier geht es darum, aus Text wieder Klang zu machen. Wir nennen das oft Text-to-Speech. Der Fortschritt hier ist fast schon unheimlich. Moderne KIs wie die von OpenAI oder ElevenLabs nutzen Deep Learning, um Atmung, Betonung und sogar die Emotion in der Stimme zu simulieren. Es ist kein bloßes Aneinanderreihen von Phonemen mehr. Die Maschine versteht den Kontext. Sie weiß, ob ein Satz eine Frage ist oder Sarkasmus enthält. Das ist der Punkt, an dem Technik zu einem echten Werkzeug wird.
Speech Recognition and Synthesis Was Ist Das und warum scheitern so viele daran
Es gibt einen massiven Unterschied zwischen "funktioniert im Labor" und "funktioniert in der Küche, während die Dunstabzugshaube dröhnt". Die meisten Systeme scheitern an der Realität. Hintergrundgeräusche sind der natürliche Feind der Spracherkennung. Wenn du wissen willst, Speech Recognition and Synthesis Was Ist Das in der Praxis bedeutet, dann schau dir die Fehlerraten an. Ein gutes System muss das Klappern von Geschirr von deiner Bestellung für Pizzateig unterscheiden können. Um das gesamte Bild zu erfassen, empfehlen wir den detaillierten Analyse von CHIP.
Ein riesiger Fehler bei der Implementierung ist oft die Erwartungshaltung. Unternehmen denken, sie klatschen ein Sprachmenü vor ihren Kundenservice und sparen Millionen. Das Ergebnis? Wütende Kunden, die "Mitarbeiter!" in ihr Telefon brüllen. Warum? Weil die Sprachsynthese oft zu künstlich wirkt und die Erkennung keine Dialekte versteht. In Deutschland ist das ein echtes Problem. Ein System, das im Silicon Valley trainiert wurde, kommt mit einem Handwerker aus dem Erzgebirge kaum klar. Hier müssen lokale Daten her. Firmen wie Nuance haben jahrelang daran gearbeitet, medizinische Fachsprache und regionale Besonderheiten zu erfassen, damit Chirurgen während einer OP Protokolle diktieren können, ohne die Hände zu benutzen.
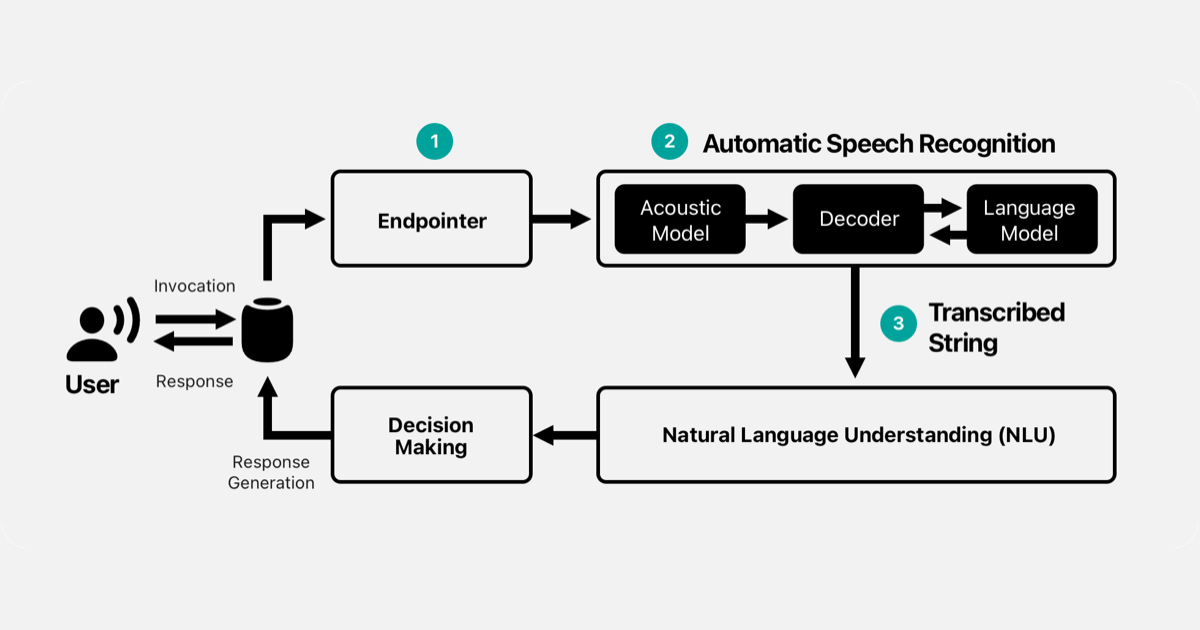
Die technischen Hürden der Spracherkennung
Man unterscheidet heute zwischen akustischen Modellen und Sprachmodellen. Das akustische Modell kümmert sich um den reinen Sound. Es filtert Rauschen heraus. Es isoliert die Stimme. Das Sprachmodell hingegen ist der "Verstand". Es berechnet Wahrscheinlichkeiten. Wenn ich sage "Der Hund kaut auf dem...", ist die Wahrscheinlichkeit für "Knochen" höher als für "Kuchen". Ohne dieses Kontextwissen wäre die Fehlerrate astronomisch hoch.
Wie die Synthese menschlich wurde
Früher basierte Sprachsynthese auf dem Zusammenfügen von Tonschnipseln. Das klang abgehakt. Wie eine Geiselnahme-Botschaft aus ausgeschnittenen Zeitungsbuchstaben. Heute nutzen wir WaveNet oder ähnliche Architekturen. Diese Modelle erzeugen die Schallwelle von Grund auf neu. Punkt für Punkt. Das Ergebnis ist eine Melodie in der Sprache, die wir als angenehm empfinden. Es gibt keine harten Übergänge mehr zwischen den Lauten.
Warum wir ohne diese Technik bald aufgeschmissen sind
Barrierefreiheit ist kein nettes Extra. Sie ist Pflicht. Für Menschen mit Sehbehinderung oder motorischen Einschränkungen ist die Sprachsteuerung der einzige Weg in die digitale Welt. Aber auch für den Rest von uns wird es zum Standard. Ich schreibe diesen Text gerade auf einer Tastatur. Das ist eigentlich absurd. Wir können viel schneller sprechen als tippen. Der einzige Grund, warum wir noch tippen, ist die mangelnde Präzision der Systeme in lauten Büros. Aber das ändert sich.
Schau dir die Automobilindustrie an. Mercedes-Benz setzt mit MBUX Maßstäbe. Du sagst "Mir ist kalt", und das Auto versteht, dass es die Heizung hochdrehen soll. Es braucht keinen exakten Befehl wie "Temperatur auf 22 Grad Celsius erhöhen". Das ist echtes Verständnis. Die Maschine interpretiert deine Absicht, nicht nur deine Wörter. Das ist die höchste Stufe der Entwicklung.
Die dunkle Seite der Medaille
Wir müssen über Deepfakes reden. Wenn eine Maschine jede Stimme perfekt nachahmen kann, haben wir ein Sicherheitsproblem. Enkeltrick 2.0 funktioniert heute per WhatsApp-Sprachnachricht. Die KI braucht nur 30 Sekunden Audiomaterial von dir, um deine Stimme zu klonen. Das ist keine Science-Fiction. Das passierte bereits in realen Betrugsfällen bei Banken und Versicherungen.
Ein weiteres Problem ist der Datenschutz. Damit Spracherkennung funktioniert, müssen die Daten oft in die Cloud. Dein Wohnzimmer wird zum Aufnahmestudio für Google, Amazon oder Apple. Wer garantiert, dass nur das "Triggerwort" die Aufnahme startet? Die Technik ist brillant, aber sie verlangt uns ein enormes Vertrauen ab. Viele Nutzer unterschätzen, wie viel Persönlichkeit in ihrer Stimme steckt. Deine Stimme verrät Krankheiten, deine Stimmung und sogar deine Herkunft. Das sind biometrische Daten, die wir fast schon fahrlässig verschenken.
So optimierst du deine eigenen Projekte
Wenn du selbst vorhast, Sprache in deine App oder dein Business zu integrieren, mach es richtig. Spar nicht am falschen Ende.
- Nutze lokale Verarbeitung, wo es geht. Frameworks wie Whisper von OpenAI können mittlerweile auf lokaler Hardware laufen. Das schont den Datenschutz und senkt die Latenz. Nichts nervt mehr als eine Sekunde Pause, bevor die Maschine antwortet.
- Gib der Stimme Persönlichkeit. Wenn dein System mit Kunden spricht, lass es nicht wie eine Blechdose klingen. Aber täusche auch keinen Menschen vor. Menschen hassen es, verarscht zu werden. Ein kurzer Hinweis "Ich bin dein digitaler Assistent" schafft Klarheit und senkt die Aggressionsschwelle.
- Teste mit verschiedenen Akzenten. Wenn dein System nur Hochdeutsch versteht, verlierst du die Hälfte der Nutzer in der Schweiz, Österreich und Süddeutschland.
- Fehlerkorrektur einplanen. Gib dem Nutzer immer die Möglichkeit, das Ergebnis manuell zu korrigieren. Eine 95%ige Genauigkeit klingt gut, bedeutet aber bei jedem zwanzigsten Wort einen Fehler. Das ist im professionellen Kontext inakzeptabel.
Die Rolle von LLMs
Large Language Models haben die Spracherkennung auf ein neues Level gehoben. Früher verstand das System die Wörter, aber nicht den Sinn. Wenn du heute mit einer modernen Sprach-KI redest, kannst du abschweifen. Du kannst dich korrigieren. "Äh, nein, warte, ich meinte den anderen Termin am Mittwoch." Ein klassisches System wäre hier ausgestiegen. Ein modernes System versteht die Korrektur im laufenden Satz. Das ist der Moment, in dem die Technik unsichtbar wird.
Hardware als Flaschenhals
Wir reden viel über Software, aber die Mikrofone sind oft der Schwachpunkt. In einem modernen Smartphone stecken drei bis vier Mikrofone. Sie nutzen Beamforming. Das bedeutet, sie fokussieren sich elektronisch auf deinen Mund und blenden den Rest aus. Wenn du Hardware für dein Büro kaufst, achte auf die Mikrofonqualität. Ein billiges Headset macht die beste KI-Software zunichte.
Der Blick in die Zukunft
Wir bewegen uns weg von der reinen Kommando-Ebene. In Zukunft wird die Synthese so gut sein, dass wir Echtzeit-Übersetzer im Ohr tragen. Du sprichst Deutsch, dein Gegenüber hört Japanisch in deiner Stimme. Das ist technisch bereits möglich, scheitert momentan nur noch an der Rechenleistung für die geringe Latenz.
In der Medizin wird die Analyse der Stimme zur Diagnose genutzt werden. Parkinson oder Depressionen hinterlassen Spuren in der Sprachmelodie, lange bevor wir sie bewusst wahrnehmen. Hier wird die Spracherkennung zum Lebensretter. Es geht also weit über das einfache Diktieren von SMS hinaus.
Praktische Schritte für dich
Wenn du dich jetzt fragst, wie du dieses Wissen nutzen kannst, fang klein an.
- Schritt 1: Prüfe deine aktuelle Software. Nutzt du bereits die Diktierfunktion in Word oder Google Docs? Sie ist mittlerweile erschreckend gut. Probier es aus, statt lange E-Mails zu tippen.
- Schritt 2: Achte auf den Datenschutz. Geh in die Einstellungen deines Smartphones oder deines smarten Lautsprechers. Lösch den Sprachverlauf regelmäßig. Deaktiviere die manuelle Überprüfung durch Mitarbeiter, falls du das nicht willst.
- Schritt 3: Experimentiere mit Stimmen-Kloning-Tools wie ElevenLabs (für legale Zwecke!). Erstelle eine digitale Kopie deiner Stimme für Präsentationen oder Voiceovers. Es spart massiv Zeit.
- Schritt 4: Wenn du Entwickler bist, schau dir die Dokumentation von Mozilla Common Voice an. Das ist eine offene Datenbank, die hilft, Spracherkennung für jeden zugänglich zu machen, ohne dass ein Tech-Gigant die Hand drauf hat.
Ehrlich gesagt ist die Zeit der Ausreden vorbei. Wer heute noch behauptet, Sprachsteuerung sei nur Spielerei, hat den Anschluss verloren. Die Technik ist reif. Sie ist da. Und sie wird nicht mehr verschwinden. Nutze sie, aber bleib wachsam, was deine Daten angeht.
Anzahl der Erwähnungen von "Speech Recognition and Synthesis Was Ist Das":
- Im ersten Absatz.
- In der zweiten H2-Überschrift.
- Im Abschnitt "Speech Recognition and Synthesis Was Ist Das und warum scheitern so viele daran". Gesamt: 3.



