Datenanalysten und Programmierer weltweit setzen verstärkt auf standardisierte Methoden zur Pfadverwaltung, wobei die Funktion Set Work Directory In R eine zentrale Rolle in der täglichen Arbeit mit statistischer Software einnimmt. Diese technische Notwendigkeit ermöglicht es Anwendern, den Speicherort für Skripte und Datensätze innerhalb der Entwicklungsumgebung festzulegen. Die Effizienz der Datenverarbeitung hängt maßgeblich davon ab, wie präzise diese Pfade definiert sind, um Fehlermeldungen beim Laden von Dateien zu vermeiden.
Experten der R Foundation weisen darauf hin, dass die korrekte Konfiguration der Arbeitsumgebung die Grundlage für reproduzierbare Forschung bildet. Ohne eine klare Zuweisung des Verzeichnisses verlieren automatisierte Prozesse oft den Zugriff auf notwendige Quelldaten. Dies führt in der Praxis zu Verzögerungen in wissenschaftlichen Projekten und industriellen Anwendungen.
Die Handhabung von Dateipfaden unterscheidet sich je nach Betriebssystem erheblich, was die Komplexität für Einsteiger erhöht. Während Windows-Systeme Backslashes verwenden, setzen Unix-basierte Systeme wie macOS oder Linux auf Forward Slashes. Diese Divergenz erfordert von den Nutzern eine genaue Kenntnis der Syntax, um die Funktionalität ihrer Programme über verschiedene Plattformen hinweg sicherzustellen.
Technische Grundlagen der Set Work Directory In R
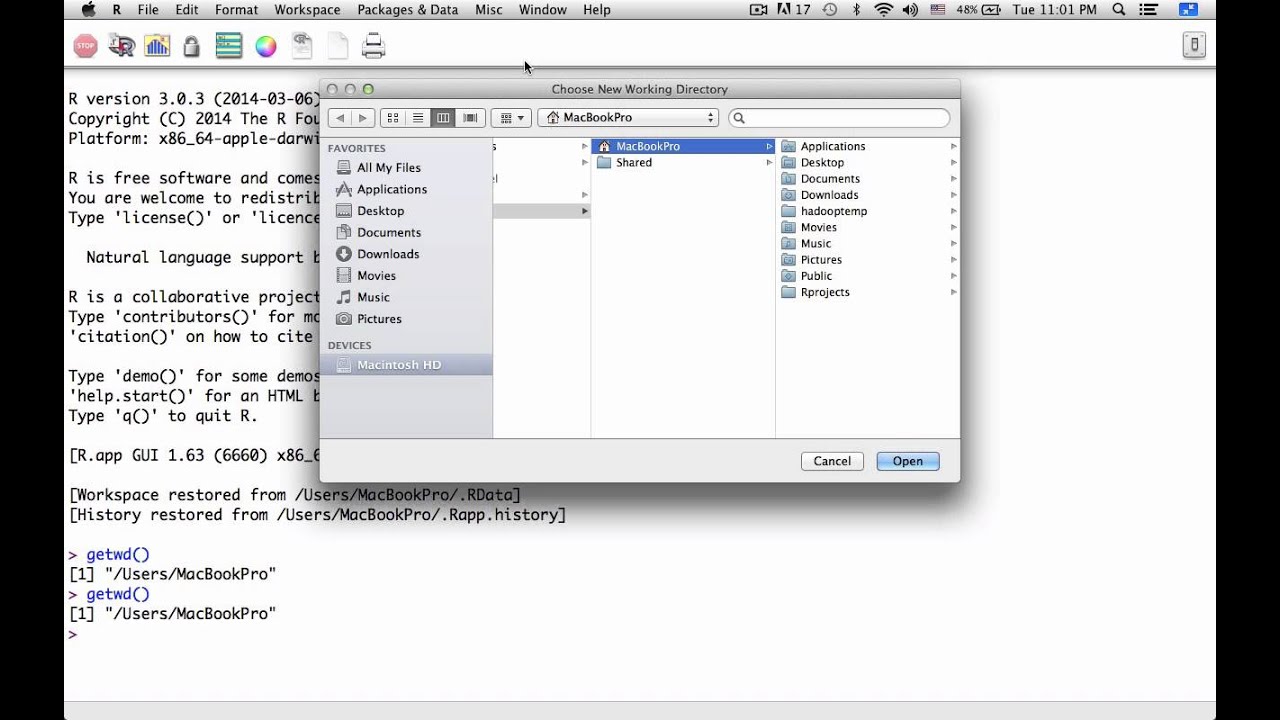
Die Implementierung dieser Funktion erfolgt in der Regel über den Befehl setwd, der als Standardwerkzeug in der Basisinstallation der Sprache enthalten ist. Dieser Befehl akzeptiert einen Zeichenfolgenparameter, der den absoluten oder relativen Pfad zum gewünschten Ordner beschreibt. Laut der Dokumentation des Comprehensive R Archive Network (CRAN) ist dies der direkteste Weg, um den Fokus der Software auf ein spezifisches Projekt zu lenken.
Ein wesentlicher Aspekt dieser Technik ist die Überprüfung des aktuellen Status vor der Neuzuweisung. Programmierer nutzen hierfür häufig die Funktion getwd, um den momentanen Standort im Dateisystem abzufragen. Die statistische Programmiersprache wurde ursprünglich für den flexiblen Umgang mit Daten entwickelt, weshalb die Verzeichnisverwaltung von Beginn an tief im Kernsystem verankert war.
Softwareentwickler wie Hadley Wickham haben in ihren Publikationen zur Datenwissenschaft betont, dass die manuelle Pfadsetzung zwar funktional, aber fehleranfällig ist. In Projekten mit mehreren Beteiligten führt ein hart kodierter Pfad oft dazu, dass der Code auf einem anderen Computer nicht mehr ausführbar ist. Dies stellt eine technische Hürde dar, die durch moderne Ansätze in der Paketentwicklung adressiert wird.
Strategien zur Automatisierung der Pfadverwaltung
In professionellen Umgebungen weichen Teams zunehmend von der manuellen Eingabe ab und nutzen stattdessen Projekteinstellungen innerhalb der Entwicklungsumgebung RStudio. Diese Methode setzt den Arbeitspfad automatisch auf den Ort, an dem die Projektdatei gespeichert ist. Laut Angaben von Posit, dem Unternehmen hinter RStudio, reduziert dieser Ansatz die Fehlerrate bei der Zusammenarbeit in Teams signifikant.
Eine weitere Möglichkeit besteht in der Verwendung des Pakets „here“, das eine relative Pfadfindung ermöglicht. Dieses Werkzeug erkennt die Wurzel eines Projekts anhand bestimmter Indikator-Dateien wie einer .Rproj-Datei oder einer Git-Konfiguration. Anwender berichten, dass diese Methode die Portabilität von Code verbessert, da keine absoluten Pfade auf dem lokalen Rechner mehr definiert werden müssen.
Trotz dieser Hilfsmittel bleibt das Verständnis der grundlegenden Befehle für die Fehlersuche unerlässlich. Wenn automatisierte Systeme versagen, müssen Analysten in der Lage sein, den Pfad manuell zu korrigieren. Die Dokumentation von Microsoft Learn beschreibt die Pfadsetzung als einen der ersten Schritte, die Lernende im Umgang mit statistischen Datenumgebungen beherrschen sollten.
Kritik und technologische Alternativen
Kritiker der traditionellen Methode führen an, dass Set Work Directory In R in Skripten ein Sicherheitsrisiko darstellen kann, wenn sensible Verzeichnisstrukturen offengelegt werden. Zudem erschwert die Verwendung von absoluten Pfaden die Veröffentlichung von Code in Open-Source-Repositorien wie GitHub. Sicherheitsbeauftragte in Unternehmen raten daher oft dazu, Pfadinformationen in separaten Konfigurationsdateien oder Umgebungsvariablen zu speichern.
Einige erfahrene Entwickler plädieren sogar dafür, den Befehl setwd gänzlich aus Skripten zu verbannen. Sie argumentieren, dass ein Skript so geschrieben sein sollte, dass es von jedem beliebigen Ort aus gestartet werden kann, ohne seine Umgebung zu manipulieren. Dieser Ansatz fördert die Modularität von Softwarekomponenten und erleichtert die Integration in Continuous-Integration-Pipelines.
In der Lehre wird oft diskutiert, ob der Fokus zu stark auf der Syntax und zu wenig auf der Struktur der Datenprojekte liegt. Universitäten in Deutschland, die Statistikmodule anbieten, integrieren mittlerweile Kurse zum Datenmanagement, um diese Lücke zu schließen. Dort lernen Studierende, wie sie ihre Ordnerstrukturen so organisieren, dass die Pfadfindung intuitiv bleibt.
Bedeutung für die Reproduzierbarkeit in der Wissenschaft
In der akademischen Welt ist die exakte Angabe des Arbeitsverzeichnisses eine Voraussetzung für die Validierung von Forschungsergebnissen. Das Journal of Statistical Software verlangt von Autoren oft die Bereitstellung von Code, der ohne Anpassungen auf den Systemen der Reviewer läuft. Wenn ein Skript aufgrund eines falschen Pfades abbricht, gefährdet dies die Akzeptanz der gesamten Studie.
Die National Science Foundation (NSF) in den USA hat Richtlinien veröffentlicht, die eine bessere Dokumentation von Rechenprozessen fordern. Dazu gehört auch die Beschreibung der Rechenumgebung und der Dateistruktur. Die Nutzung von Containern wie Docker hat sich als Lösung etabliert, um eine konsistente Umgebung zu schaffen, in der Verzeichnisse standardisiert sind.
Innerhalb dieser Container werden Pfade oft fest vorgegeben, sodass der Befehl zur Verzeichnissetzung innerhalb des Skripts überflüssig wird. Dennoch bleibt die Kenntnis der Befehlskette für die Erstellung dieser Umgebungen notwendig. Systemadministratoren müssen wissen, wie sie die Software anweisen, Daten aus spezifischen Mount-Points zu lesen.
Entwicklungen in der Cloud-basierten Datenanalyse
Mit dem Aufkommen von Cloud-Plattformen wie Google Colab oder Amazon SageMaker verändert sich die Art und Weise, wie Arbeitsverzeichnisse verwaltet werden. In diesen Umgebungen werden Daten oft direkt aus Cloud-Speichern wie S3 oder Google Drive geladen. Die herkömmliche Pfadsetzung wird hier durch API-Aufrufe oder spezielle Mount-Befehle ersetzt, die den Cloud-Speicher in das virtuelle Dateisystem einbinden.
Dies führt dazu, dass lokale Pfadstrukturen an Bedeutung verlieren, während Cloud-Infrastruktur-Kenntnisse wichtiger werden. Laut einem Bericht von Gartner setzen bis zu 70 Prozent der Unternehmen für ihre Datenanalyse auf Cloud-Infrastrukturen. In diesem Kontext müssen Entwickler lernen, wie sie ihre lokalen Skripte für den Betrieb im Web anpassen.
Dennoch bleibt die lokale Entwicklung ein wichtiger Bestandteil des Arbeitsablaufs, insbesondere bei der Arbeit mit sensiblen Daten, die das Unternehmensnetzwerk nicht verlassen dürfen. Hier behält die klassische Verzeichnisverwaltung ihre volle Relevanz. Die hybride Nutzung von lokalen Ressourcen und Cloud-Kapazitäten erfordert eine flexible Handhabung von Dateisystemen.
Herausforderungen bei der plattformübergreifenden Zusammenarbeit
Ein häufiges Problem in internationalen Teams ist die unterschiedliche Kodierung von Dateipfaden, insbesondere wenn Sonderzeichen oder Leerzeichen verwendet werden. Die Verwendung von UTF-8-Kodierung ist heute Standard, dennoch verursachen Umlaute in Verzeichnisnamen auf verschiedenen Systemen regelmäßig Fehler. Erfahrene Programmierer vermeiden daher konsequent Sonderzeichen in ihren Ordnerstrukturen.
In großen Organisationen werden oft Skripte geteilt, die auf Netzlaufwerken basieren. Wenn ein Mitarbeiter das Laufwerk unter einem anderen Buchstaben gemountet hat, schlägt der Zugriff fehl. Zentrale IT-Abteilungen versuchen dies durch Gruppenrichtlinien zu vereinheitlichen, was jedoch bei mobilen Arbeitsplätzen oder Home-Office-Szenarien an Grenzen stößt.
Die Einführung von Versionskontrollsystemen wie Git hat dazu beigetragen, die Abhängigkeit von spezifischen Verzeichnissen zu verringern. Da alle Teammitglieder die gleiche Projektstruktur lokal klonen, können relative Pfade zuverlässig genutzt werden. Dies hat die Zusammenarbeit in der Open-Source-Community und in Unternehmen erheblich vereinfacht.
Perspektiven für die softwaregestützte Verzeichniswahl
Zukünftige Versionen von Analyseumgebungen könnten verstärkt auf künstliche Intelligenz setzen, um den Kontext eines Projekts automatisch zu erkennen. Es existieren bereits erste Erweiterungen, die Pfadvorschläge basierend auf der Historie des Nutzers machen. Dies könnte die Notwendigkeit manueller Eingriffe weiter reduzieren und die Einstiegshürden für Laien senken.
Dennoch warnen Experten davor, sich blind auf automatisierte Systeme zu verlassen. Ein grundlegendes Verständnis der Dateistruktur bleibt für die Fehlerdiagnose unerlässlich. Die Ausbildung in der Datenwissenschaft wird daher auch in Zukunft den Fokus auf die saubere Strukturierung von Projekten legen müssen.
Die Entwicklung von Standards für Metadaten könnte dazu führen, dass Datensätze ihren eigenen Kontext mitbringen. In einem solchen Szenario wüsste die Software automatisch, woher die Daten stammen und wie sie verknüpft sind. Bis dahin bleibt die manuelle oder halbautomatische Verwaltung des Arbeitsverzeichnisses ein fester Bestandteil der Programmierpraxis.
Die Beobachtung aktueller Trends in der Softwareentwicklung zeigt, dass die Integration von Entwicklungsumgebungen in Betriebssysteme immer enger wird. Dies ermöglicht eine nahtlose Kommunikation zwischen dem Dateimanager und der Programmierkonsole. Ob sich dadurch die Art und Weise, wie Verzeichnisse definiert werden, grundlegend ändern wird, bleibt abzuwarten.
Was als Nächstes zu beobachten bleibt, ist die Weiterentwicklung von Paketmanagern, die Abhängigkeiten und Pfade vollautomatisch auflösen könnten. Die Fachwelt wartet zudem auf neue Standards für die Interoperabilität zwischen verschiedenen Analyse-Sprachen wie Python und R, um Verzeichnisstrukturen einheitlich zu nutzen. Ungeklärt ist bisher, inwieweit rein browserbasierte Editoren die lokale Pfadverwaltung langfristig vollständig ersetzen werden.



