Manchmal fühlt sich die Arbeit mit Text in .NET wie der Versuch an, einen gordischen Knoten mit einer Nagelscheibe zu lösen. Du hast eine Zeichenfolge, willst einen Teil davon loswerden oder austauschen und merkst plötzlich, dass die Standardmethode gar nicht so simpel ist, wie sie auf den ersten Blick scheint. Wenn du versuchst, Replace String In String C# in deinem Code umzusetzen, stößt du schnell auf Fragen der Performance, der Groß- und Kleinschreibung oder der Unveränderlichkeit von Objekten. Ich habe hunderte Stunden damit verbracht, Speicherlecks in großen Datenverarbeitungssystemen zu jagen, nur weil jemand dachte, dass ein einfaches Ersetzen in einer Schleife harmlos sei. Es ist nicht harmlos. Es ist die Basis für effiziente Software.
Warum Replace String In String C# mehr als nur eine Methode ist
In der Welt von C# sind Zeichenfolgen unveränderlich (immutable). Das bedeutet: Jedes Mal, wenn du einen Text manipulierst, erzeugst du im Hintergrund ein komplett neues Objekt im Arbeitsspeicher. Stell dir vor, du hast ein Buch und möchtest ein Wort auf Seite 50 ändern. Anstatt zu radieren, kopiert C# das gesamte Buch, setzt das neue Wort ein und wirft das alte Buch weg. Das ist bei einem Satz egal. Bei einer Log-Datei mit zehn Millionen Zeilen ist das der sichere Weg, deine Anwendung in die Knie zu zwingen. Für eine detailliertere Darstellung zu diesem Bereich, lesen Sie: diesen verwandten Artikel.
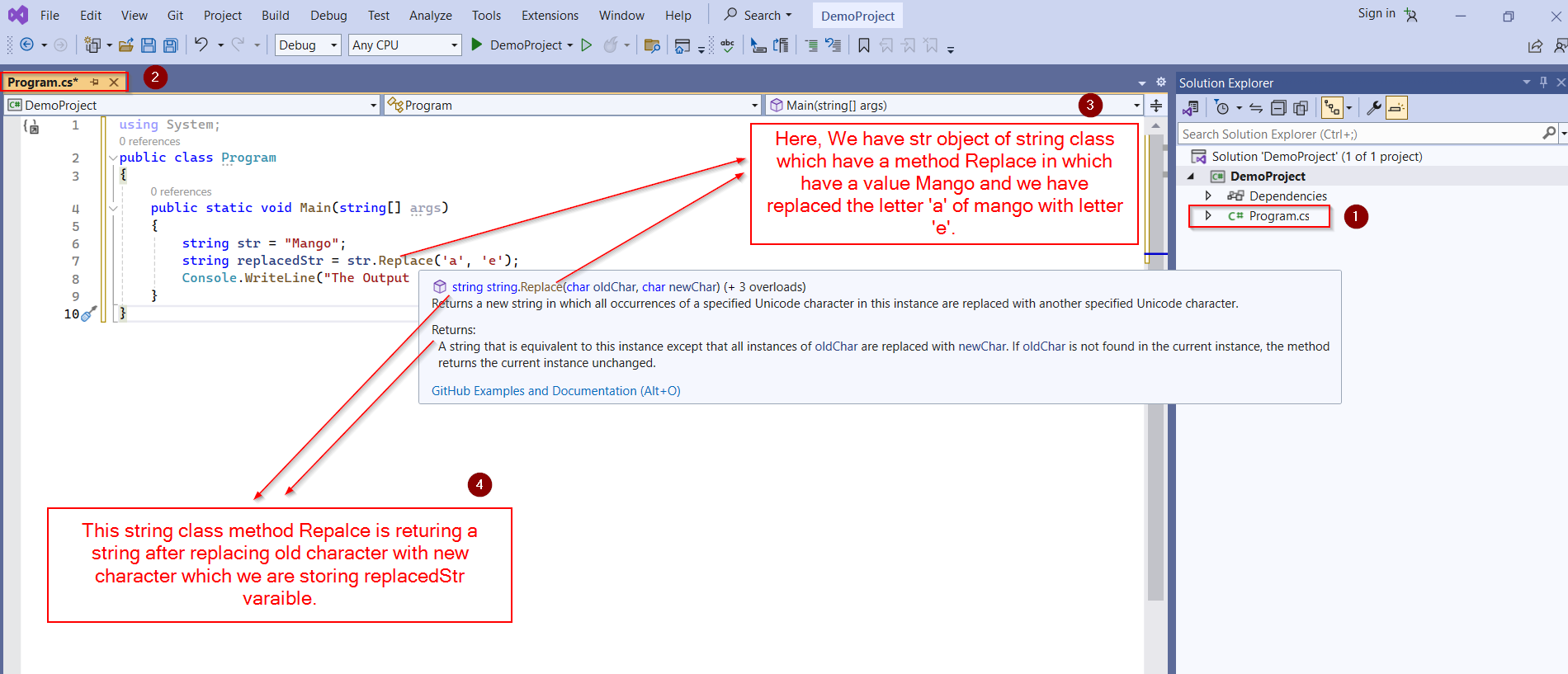
Die gängigste Methode ist die eingebaute Funktion der Klasse System.String. Du rufst sie auf, übergibst das Zielwort und den Ersatz, und fertig. Aber was passiert, wenn der Text gar nicht exakt so geschrieben ist, wie du denkst? Standardmäßig achtet die Funktion penibel auf jedes kleine und große Zeichen. Ein "Apfel" ist für das Programm etwas völlig anderes als ein "apfel".
Die Tücken der Standardmethode
Die einfache Methode nimmt zwei Parameter. Sie gibt eine neue Zeichenfolge zurück. Das ist der Punkt, an dem viele Anfänger scheitern: Sie vergessen, das Ergebnis einer Variablen zuzuweisen. Sie schreiben den Befehl einfach hin und wundern sich, warum sich der ursprüngliche Text nicht verändert hat. Da Zeichenfolgen unveränderlich sind, muss man das Ergebnis immer auffangen. Wer das ignoriert, produziert Code, der zwar läuft, aber absolut nichts tut. Für umfassendere Hintergründe zu diesem Thema ist eine umfassende Analyse bei Computer Bild verfügbar.
Performance im Blick behalten
Wenn du in einer Schleife tausende Male Texte austauschst, solltest du einen weiten Bogen um die normale Ersetzung machen. Hier kommt der StringBuilder ins Spiel. Er arbeitet mit einem Puffer. Er kopiert nicht ständig alles neu. Das spart massiv Zeit und schont den Garbage Collector. In Tests zeigt sich oft, dass die Verwendung des Puffers bei großen Operationen bis zu 90 Prozent schneller sein kann als die herkömmliche Variante. Das ist kein kleiner Unterschied. Das ist der Unterschied zwischen einer flüssigen App und einer, die ständig einfriert.
Strategien für Replace String In String C# in der Praxis
Es gibt Situationen, in denen die einfache Ersetzung nicht ausreicht. Was ist, wenn du nur das erste Vorkommen eines Wortes tauschen willst? Die Standardmethode in .NET ersetzt gnadenlos alles. Wenn du einen Text hast, in dem "Berlin" dreimal vorkommt, du aber nur das erste "Berlin" durch "München" ersetzen willst, stehst du vor einem Problem.
Hier musst du selbst Hand anlegen. Eine Kombination aus IndexOf und Substring ist der klassische Weg. Du suchst die Position des Wortes. Dann schneidest du den Text davor aus, fügst deinen Ersatz ein und hängst den Rest hinten dran. Das klingt mühsam. Ist es auch. Aber es gibt dir die volle Kontrolle. Viele Entwickler unterschätzen, wie oft man diese chirurgische Präzision im Alltag braucht, besonders wenn man strukturierte Daten wie CSV oder einfache Dateiformate parst.
Umgang mit Groß- und Kleinschreibung
Seit .NET Core und den neueren Versionen von .NET haben wir endlich eine Überladung der Methode, die ein StringComparison-Enum akzeptiert. Das ist ein Segen. Früher mussten wir den Text mühsam in Kleinbuchstaben umwandeln, nur um einen Vergleich durchzuführen. Das hat nicht nur mehr Speicher verbraucht, sondern war auch fehleranfällig bei Sonderzeichen oder kulturellen Unterschieden. Heute sagst du dem Programm einfach: "Ignoriere die Gehäuseart". Das macht den Code sauberer und verständlicher.
Reguläre Ausdrücke als Geheimwaffe
Wenn die Logik komplexer wird, greifen Profis zu Regex.Replace. Stell dir vor, du willst alle Zahlen in einem Text durch ein Sternchen ersetzen. Oder du willst Wörter finden, die mit einem bestimmten Buchstaben anfangen. Mit der normalen Methode hast du hier keine Chance. Reguläre Ausdrücke sind mächtig, aber sie haben ihren Preis. Sie sind langsamer. Sie verbrauchen mehr CPU-Zyklen. Ich nutze sie nur, wenn es wirklich nötig ist. Wenn ein einfaches Ersetzen reicht, bleib dabei. Die Komplexität von Regex führt oft zu Fehlern, die man erst Wochen später bemerkt, wenn ein Nutzer ein ganz spezielles Sonderzeichen eingibt.
Effizienz und Speicheroptimierung bei Textoperationen
Wer professionelle Software schreibt, muss wissen, was unter der Haube passiert. Das Framework Microsoft .NET bietet heute Werkzeuge wie Span<T>. Das ist ein fortgeschrittenes Konzept. Es erlaubt uns, auf Teilen eines Textes zu arbeiten, ohne neue Objekte zu erstellen. Wenn du Performance-kritische Anwendungen schreibst, etwa für den Finanzsektor oder zur Echtzeit-Datenverarbeitung, ist das dein Goldstandard.
Warum einfache Zuweisungen oft täuschen
In C# ist ein String ein Referenztyp. Aber er verhält sich fast wie ein Werttyp. Das verwirrt viele. Wenn du zwei Variablen hast, die auf den gleichen Text zeigen, und du eine davon änderst, bleibt die andere unberührt. Das liegt wieder an der Unveränderlichkeit. Wer das verstanden hat, versteht auch, warum das ständige Kopieren von Daten in großen Systemen so gefährlich ist. In der Cloud-Entwicklung zahlst du für CPU-Zeit und Speicher. Ein ineffizientes System zum Ersetzen von Texten kann deine monatliche Rechnung bei Anbietern wie Azure spürbar nach oben treiben.
Die Rolle des Garbage Collectors
Jedes Mal, wenn eine Zeichenfolge weggeworfen wird, muss der Garbage Collector (GC) ran. Er räumt den Speicher auf. Wenn du zu viele kleine Objekte in kurzer Zeit erzeugst, muss der GC öfter pausieren. Deine App ruckelt. In modernen Webservices, die tausende Anfragen pro Sekunde verarbeiten, führt das zu Latenzproblemen. Ich habe Systeme gesehen, die durch den Wechsel auf StringBuilder plötzlich doppelt so viele Anfragen pro Sekunde bewältigen konnten. Es ist oft die kleinste Stelle im Code, die den größten Flaschenhals verursacht.
Fortgeschrittene Szenarien und Sonderfälle
Manchmal willst du nicht nur einen Text gegen einen anderen tauschen. Manchmal basiert der Ersatz auf dem Fund selbst. Regex.Replace erlaubt die Verwendung eines MatchEvaluator. Das ist eine Funktion, die jedes Mal aufgerufen wird, wenn ein Treffer erzielt wurde. Du kannst darin entscheiden, was als Ersatz dienen soll. Vielleicht willst du einen gefundenen Wert in einer Datenbank nachschlagen? Oder eine mathematische Operation darauf anwenden?
Kulturelle Unterschiede und Unicode
Ein riesiges Thema, das oft ignoriert wird, ist die Internationalisierung. Ein "i" ist in der Türkei nicht dasselbe wie in Deutschland. Wenn du Texte ersetzt, die Benutzereingaben aus verschiedenen Ländern enthalten, musst du die CultureInfo beachten. Die Standard-Ersetzung nutzt meistens die aktuelle Kultur des Betriebssystems. Das kann zu bösen Überraschungen führen, wenn dein Server in den USA steht, aber deutsche Nutzer bedient. Nutze immer explizit StringComparison.Ordinal oder StringComparison.InvariantCulture, wenn du technische Daten wie IDs oder Pfade bearbeitest.
Arbeiten mit großen Dateien
Wenn du eine 2 GB große Textdatei hast, kannst du nicht einfach File.ReadAllText und dann eine Ersetzung aufrufen. Dein RAM würde sofort explodieren. Hier musst du strömen (Streaming). Du liest die Datei Zeile für Zeile, führst die Ersetzung durch und schreibst sie sofort wieder weg. Das ist die einzig sichere Methode, um mit massiven Datenmengen umzugehen. Es dauert vielleicht ein paar Millisekunden länger, aber es ist stabil.
Fehlervermeidung und Best Practices
Der häufigste Fehler ist die Annahme, dass der gesuchte Teilstring vorhanden ist. Was passiert, wenn er fehlt? Die Methode gibt einfach den Originaltext zurück. Keine Exception, kein Fehler. Das ist meistens gut, aber manchmal willst du wissen, ob überhaupt etwas passiert ist. In diesem Fall musst du vorher prüfen oder das Ergebnis vergleichen.
Die Gefahr von Null-Referenzen
Ein Klassiker: Du rufst die Methode auf einer Variable auf, die null ist. Peng. Deine Anwendung stürzt ab. In modernem C# helfen uns die Nullable Reference Types, das zu verhindern. Aber man muss sie auch nutzen. Prüfe immer, ob der Text, in dem du suchen willst, überhaupt existiert. Ein einfacher Check am Anfang spart dir stundenlange Fehlersuche in Logfiles.
Zeichenfolgen verketten vs. Ersetzen
Oft sehe ich Code, der Texte erst mühsam zusammensetzt, nur um danach Teile wieder zu ersetzen. Das ist Wahnsinn. Wenn du weißt, wie das Endergebnis aussehen soll, nutze von Anfang an String-Interpolation oder den StringBuilder. Ersetzen sollte die letzte Instanz sein, wenn du einen bestehenden Text bekommst, auf dessen Erzeugung du keinen Einfluss hattest.
Praktische Beispiele für den Alltag
Nehmen wir an, du entwickelst ein System für die deutsche Verwaltung. Du musst in einem Dokument Platzhalter wie [NAME] durch echte Daten ersetzen.
- Erstelle eine Liste aller Ersetzungen.
- Nutze einen
StringBuilder, wenn es viele Platzhalter sind. - Achte darauf, dass die Platzhalter eindeutig sind. Wenn du nur
NAMEschreibst, wird vielleicht auch das Wort "Binnengewässer" kaputt gemacht. - Teste mit Sonderzeichen wie Umlauten (ä, ö, ü) und dem scharfen S (ß).
Hier zeigt sich die wahre Qualität eines Entwicklers. Es geht nicht darum, dass es einmal funktioniert. Es geht darum, dass es immer funktioniert, egal wie seltsam die Eingabe ist. Ein robustes System fängt leere Eingaben ab, geht mit riesigen Texten um und bleibt dabei schnell.
Die Wahl der richtigen Methode
Wann nimmst du was? Hier ist eine einfache Faustregel. Für eine einzelne Ersetzung in einem kurzen Text nimmst du string.Replace. Für komplexe Muster oder Regeln nimmst du Regex. Für massenhafte Änderungen in einer Schleife nimmst du den StringBuilder. Für maximale Performance bei riesigen Datenmengen nutzt du Span<T>.
Ein Wort zu Drittanbieter-Bibliotheken
Es gibt Pakete auf NuGet, die versprechen, alles schneller und besser zu machen. In 99 Prozent der Fälle brauchst du sie nicht. Das .NET-Framework ist mittlerweile so hochoptimiert, dass die Standardwerkzeuge fast unschlagbar sind. Bevor du eine neue Abhängigkeit in dein Projekt holst, miss die Geschwindigkeit selbst. Meistens liegt der Fehler im eigenen Algorithmus, nicht im Framework.
Die Zukunft der Textverarbeitung in C#
Mit jeder neuen Version von C# und .NET kommen neue Optimierungen. Die Ingenieure bei Microsoft arbeiten ständig daran, wie Zeichenfolgen im Speicher verwaltet werden. Wir sehen einen Trend hin zu "Zero Allocation"-Programmierung. Das Ziel ist es, Text zu verarbeiten, ohne jemals neuen Speicher auf dem Heap anzufordern. Das ist für die meisten Webentwickler vielleicht nicht lebensnotwendig, aber es zeigt, wo die Reise hingeht.
Wenn du heute lernst, wie du effizient mit Texten umgehst, bist du für die Zukunft gerüstet. Es geht um das Verständnis von Speicher, CPU und der Logik hinter den Zeichen. Ein guter Entwickler weiß nicht nur, welche Methode er aufrufen muss. Er weiß, was diese Methode mit dem Computer macht.
Praktische nächste Schritte für deinen Code
Jetzt ist es an der Zeit, dein Wissen in die Tat umzusetzen. Schau dir deine aktuellen Projekte an.
- Suche nach Stellen, an denen du Texte in Schleifen bearbeitest. Ersetze sie durch den
StringBuilder, wenn die Anzahl der Iterationen groß ist. - Überprüfe, ob du die Groß- und Kleinschreibung korrekt behandelst. Nutze
StringComparison, um Fehler durch unterschiedliche Schreibweisen zu vermeiden. - Teste deine Anwendung mit extrem langen Texten. Schau im Task-Manager oder in den Visual Studio Diagnostic Tools, wie der Speicherverbrauch nach oben schießt.
- Implementiere Null-Checks vor jeder Textoperation, um Abstürze zu verhindern.
- Wenn du Regex nutzt, überlege, ob es eine einfachere Methode gibt. Regex ist schwer zu lesen und schwer zu warten. Ein einfacherer Code ist fast immer besserer Code.
Effiziente Textmanipulation ist kein Hexenwerk. Es erfordert nur Aufmerksamkeit und die Bereitschaft, hinter die Kulissen der bequemen Methoden zu blicken. Wer diese Prinzipien verinnerlicht, schreibt Software, die nicht nur funktioniert, sondern auch unter Last stabil bleibt.



