Wer glaubt, dass Softwareentwicklung lediglich aus dem logischen Zusammensetzen von Bausteinen besteht, hat noch nie versucht, ein System zu retten, das unter der Last seiner eigenen Ineffizienz zusammenbricht. Es gibt eine gefährliche Bequemlichkeit in der Art und Weise, wie wir Code schreiben. Viele Entwickler greifen reflexartig zu Standardlösungen, weil sie im Studium oder in Online-Foren als Best Practice verkauft wurden. Ein klassisches Beispiel dafür ist das Reading A File In Java Line By Line, eine Technik, die so banal klingt, dass kaum jemand ihre strukturellen Abgründe hinterfragt. Wir gehen davon aus, dass das sequentielle Einlesen von Daten der sicherste Weg ist, um den Arbeitsspeicher zu schonen. Das klingt logisch. Es fühlt sich richtig an. Doch in der harten Realität von Hochleistungssystemen und massiven Datenströmen ist dieser zeilenweise Ansatz oft nichts weiter als eine kontrollierte Verlangsamung, die das eigentliche Problem der Datenverarbeitung nur verschleiert, statt es zu lösen.
Die Illusion der Ressourcenschonung
Der Mythos besagt, dass man durch das Einlesen einzelner Zeilen die volle Kontrolle über den Heap-Speicher behält. Man stellt sich vor, wie die Daten fein säuberlich portioniert durch die Pipeline fließen. In der Theorie verhindert das den gefürchteten OutOfMemoryError. Ich habe jedoch oft genug erlebt, wie genau dieser Ansatz in einer Sackgasse endet. Das Problem liegt im Overhead. Jede Zeile, die wir einzeln anfassen, erfordert eine Interaktion mit dem zugrunde liegenden Stream, eine Prüfung auf Zeilenumbrüche und oft die Erzeugung eines neuen String-Objekts im Speicher. Wenn wir über Millionen von Zeilen sprechen, erzeugen wir eine gigantische Menge an kurzlebigen Objekten, die den Garbage Collector in den Wahnsinn treiben. Es ist ein klassischer Fall von gut gemeint, aber schlecht umgesetzt. Wir tauschen ein potenzielles Speicherproblem gegen ein massives Performanceproblem und eine erhöhte CPU-Last ein. Das ist kein fairer Handel. Es ist eine technische Bankrotterklärung, die wir nur akzeptieren, weil wir die Alternativen scheuen.
Man muss sich vor Augen führen, was hinter den Kulissen passiert, wenn ein Programm eine Datei öffnet. Das Betriebssystem liest ohnehin in Blöcken. Wenn die Java Virtual Machine dann künstlich auf jede einzelne Zeile wartet, unterbrechen wir den natürlichen Fluss der Daten. Wir zwingen die Hardware dazu, in einem Rhythmus zu arbeiten, der ihrer Architektur widerspricht. Es gibt Szenarien in der modernen Datenverarbeitung, in denen das traditionelle Modell schlichtweg versagt. Wer heute noch glaubt, dass einfache Pufferung alle Sorgen löst, hat die Komplexität aktueller Cloud-Infrastrukturen nicht verstanden. Dort kostet jede Millisekunde Rechenzeit bares Geld. Eine ineffiziente Leseschleife ist somit nicht nur ein technisches Ärgernis, sondern ein finanzielles Leck.
Die versteckten Gefahren beim Reading A File In Java Line By Line
Es geht nicht nur um die Geschwindigkeit. Ein oft übersehener Aspekt ist die Semantik der Daten. Dateien sind selten so sauber strukturiert, wie es Lehrbücher suggerieren. Was passiert, wenn eine Zeile plötzlich zwei Gigabyte groß ist? Was geschieht bei inkonsistenten Zeilenendungen in einer verteilten Umgebung? Der naive Ansatz beim Reading A File In Java Line By Line bricht hier sofort zusammen. Er verlässt sich auf eine Konsistenz, die in der freien Wildbahn der IT-Systeme nicht existiert. Ich habe Systeme gesehen, die abstürzten, weil ein Logging-Framework eine einzige, astronomisch lange Zeile produzierte, die den Puffer sprengte. Die Annahme, dass eine Zeile eine handliche Einheit darstellt, ist eine gefährliche Vereinfachung.
Wenn Puffer zur Falle werden
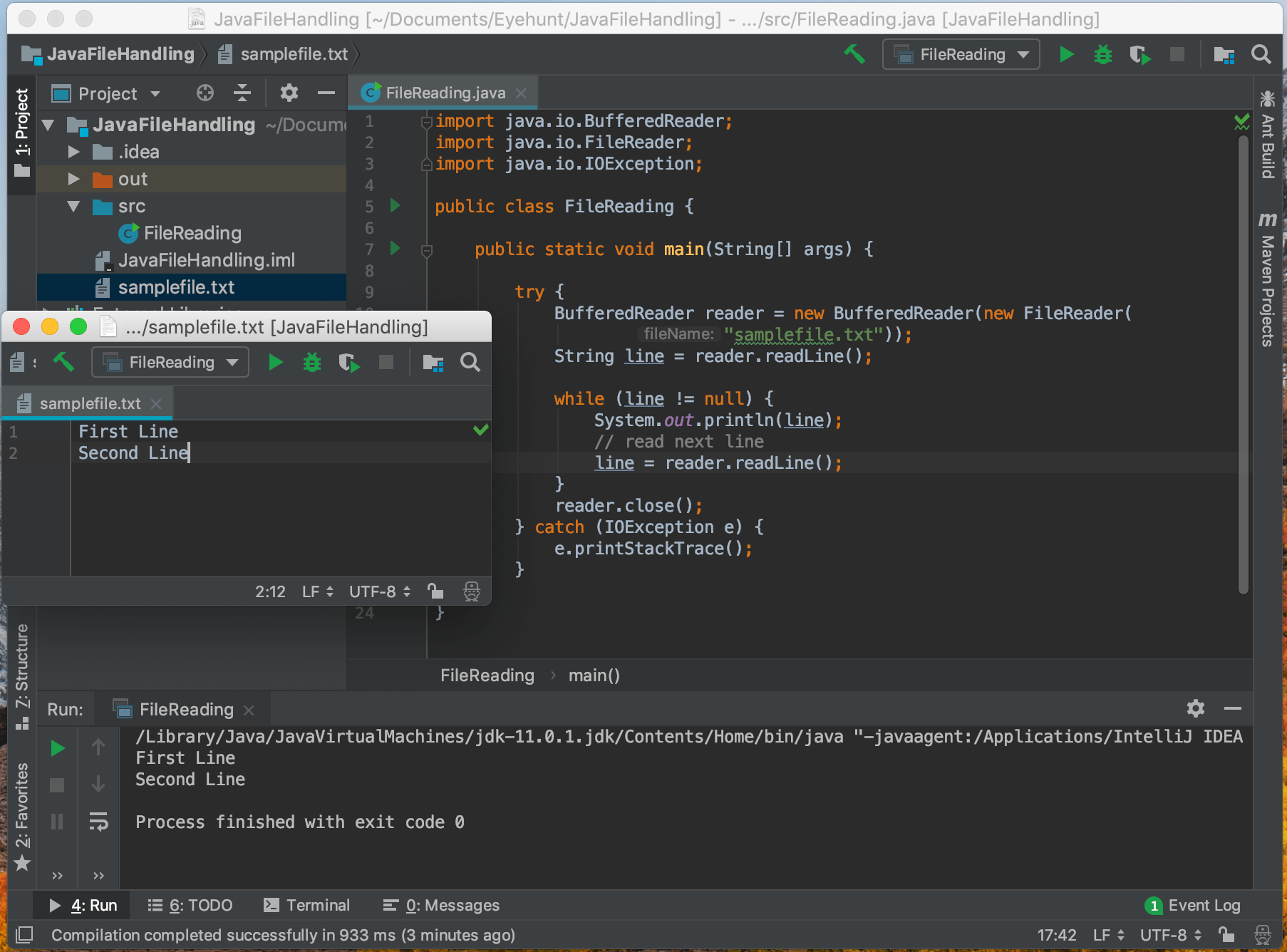
In der Standardbibliothek von Java gibt es Werkzeuge wie den BufferedReader. Er ist das Arbeitstier für viele Aufgaben. Doch er ist ein Relikt aus einer Zeit, in der Dateien klein und Festplatten langsam waren. Heute arbeiten wir mit NVMe-Speichern, die Datenraten erreichen, von denen Entwickler vor zwanzig Jahren nur träumten. Ein Standardpuffer von 8192 Bytes ist in diesem Kontext fast schon lächerlich klein. Wer diesen Wert nicht manuell anpasst, lässt wertvolle Leistung auf der Strecke. Doch selbst mit einem größeren Puffer bleibt das Grundproblem bestehen: Die synchrone Verarbeitung. Während wir auf die nächste Zeile warten, langweilt sich der Prozessor. Wir nutzen die parallelen Fähigkeiten moderner CPUs nicht aus, weil wir uns sklavisch an das sequentielle Modell klammern.
Kritiker werden nun einwenden, dass Komplexität vermieden werden sollte. Sie sagen, dass ein einfacher Code leichter zu warten ist. Das stimmt natürlich. Aber Wartbarkeit darf kein Deckmantel für Inkompetenz sein. Wenn eine Anwendung unter Last einknickt, nützt es niemandem, dass der Quellcode leicht zu lesen war. Man kann Robustheit und Eleganz miteinander verbinden, ohne in die Falle der Zeilen-für-Zeile-Mentalität zu tappen. Es erfordert lediglich ein tieferes Verständnis dafür, wie Java mit dem Dateisystem interagiert. Wir müssen lernen, in Datenströmen und Batches zu denken, statt in einzelnen Sätzen.
Warum wir die Kontrolle über den Stream abgeben müssen
Die moderne Lösung liegt oft in der reaktiven Programmierung oder der Verwendung von Memory Mapped Files. Hier wird die Datei direkt in den virtuellen Adressraum des Prozesses abgebildet. Das Betriebssystem übernimmt das Paging und das Laden der Daten. Das ist effizienter als alles, was wir manuell mit Schleifen bauen könnten. Dennoch schrecken viele davor zurück. Es wirkt zu komplex, zu nah an der Hardware. Doch genau dort findet die echte Softwareentwicklung statt. Wer sich weigert, diese Mechanismen zu verstehen, wird immer nur an der Oberfläche kratzen.
Der Irrtum der einfachen API
Java hat uns mit den Streams in Version 8 ein mächtiges Werkzeug an die Hand gegeben. Files.lines() wirkt wie eine Erlösung. Es sieht sauber aus, ist funktional und scheint alle Probleme zu lösen. Doch unter der Haube ist es oft nur eine hübsche Verpackung für die alten Mechanismen. Es verleitet dazu, komplexe Operationen auf die Daten anzuwenden, während der Stream noch offen ist. Wenn man vergisst, diesen Stream in einem Try-with-Resources-Block zu schließen, riskiert man File-Handle-Leaks, die im schlimmsten Fall den gesamten Server lahmlegen. Es ist diese trügerische Einfachheit, die zu Nachlässigkeit führt. Wir verlassen uns darauf, dass die Sprache alles für uns regelt, und verlieren dabei den Blick für die physischen Realitäten der Hardware.
Ich erinnere mich an ein Projekt, bei dem ein Team tagelang nach einem Speicherleck suchte. Am Ende stellte sich heraus, dass sie massenweise kleine Dateien einlasen und die Streams nicht korrekt schlossen. Sie dachten, der Garbage Collector würde das schon richten. Aber Datei-Handles sind knappe Systemressourcen, keine Java-Objekte, die man einfach ignorieren kann. Solche Fehler passieren nicht, weil die Entwickler schlecht sind, sondern weil sie der Abstraktion zu sehr vertrauen. Wir müssen wieder lernen, skeptisch gegenüber den bequemen Wegen zu sein.
Eine neue Perspektive auf den Datenfluss
Was ist also die Alternative? Müssen wir jedes Mal das Rad neu erfinden? Sicherlich nicht. Aber wir müssen aufhören, das Lesen von Dateien als eine triviale Aufgabe zu betrachten. Es ist eine der kritischsten I/O-Operationen überhaupt. Ein erfahrener Architekt betrachtet den Datenfluss als Ganzes. Er fragt sich, woher die Daten kommen, wohin sie gehen und welche Transformationen wirklich notwendig sind. Manchmal ist der beste Weg, eine Datei zu verarbeiten, sie gar nicht erst in Zeilen zu zerlegen. Vielleicht reicht ein binärer Scan? Vielleicht können wir die Datei in festen Blöcken verarbeiten und die Logik darauf anpassen?
Ein oft unterschätzter Faktor ist die Zeichenkodierung. Wer beim Einlesen nicht explizit ein Charset angibt, begibt sich auf dünnes Eis. Das Programm verhält sich auf dem Entwicklerrechner unter Windows anders als auf dem Produktionsserver unter Linux. Es sind diese kleinen Details, die den Unterschied zwischen einem Amateur und einem Profi ausmachen. Ein professioneller Umgang mit Dateisystemen erfordert Disziplin. Es erfordert den Mut, den Standardweg zu verlassen, wenn er nicht mehr ausreicht. Wir müssen die Werkzeuge nutzen, die uns maximale Performance bei minimalem Risiko bieten. Das bedeutet oft, NIO.2 zu verwenden und sich mit Kanälen und Buffern auseinanderzusetzen, statt nur mit Readern und Writern.
Man kann die Effizienz drastisch steigern, wenn man das Betriebssystem die Arbeit machen lässt. Asynchrones I/O ist kein Hexenwerk mehr. Es erlaubt uns, Daten zu lesen, während wir bereits die vorherigen Pakete verarbeiten. Das ist echte Parallelität. Das ist das, was moderne Hardware verlangt. Wer sich darauf einlässt, wird feststellen, dass der Code zwar etwas anspruchsvoller wird, aber die Belohnung in Form von Stabilität und Geschwindigkeit es absolut wert ist. Wir sollten aufhören, uns mit dem Minimum zufrieden zu geben, nur weil es funktioniert. In einer Welt, in der Datenmengen exponentiell wachsen, ist "funktioniert irgendwie" nicht mehr gut genug.
Das Ende der Zeilen-Mentalität
Es ist an der Zeit, dass wir unser Verständnis von I/O-Operationen grundlegend reformieren. Das ständige Festhalten am Reading A File In Java Line By Line als Standardlösung ist ein Symptom für eine tiefere Angst vor der Komplexität unter der Oberfläche. Wir verstecken uns hinter einfachen APIs, weil wir die Konsequenzen der Hardware-Interaktion nicht wahrhaben wollen. Doch die Realität holt uns immer ein, meistens nachts um drei, wenn die Server unter der Last der Datenverarbeitung zusammenbrechen. Wir müssen lernen, dass Effizienz kein optionales Feature ist, sondern die Basis jeder professionellen Software.
Wenn wir über den Tellerrand der Java-Standardbibliothek hinausblicken, sehen wir, dass andere Ökosysteme viel radikaler mit diesen Themen umgehen. In der Welt der Big-Data-Verarbeitung wird kaum noch jemand auf die Idee kommen, eine Datei zeilenweise auf einem einzelnen Thread zu lesen. Dort werden Daten partitioniert, verteilt und parallel verarbeitet. Java bietet uns alle Werkzeuge, um diese Konzepte auch in kleineren Anwendungen umzuzusetzen. Wir müssen sie nur nutzen. Es beginnt damit, die Zeile als kleinste Einheit der Verarbeitung zu hinterfragen. Wir müssen die Datei als das sehen, was sie ist: ein kontinuierlicher Strom von Bytes, den wir so effizient wie möglich in Informationen verwandeln müssen.
Die echte Meisterschaft in der Programmierung zeigt sich nicht darin, wie viele Frameworks man beherrscht. Sie zeigt sich darin, wie man mit den grundlegendsten Operationen umgeht. Das Lesen einer Datei ist das Fundament vieler Anwendungen. Wenn dieses Fundament wackelig ist, wird das gesamte Gebäude niemals sicher stehen. Wir brauchen eine Kultur der Präzision. Wir brauchen Entwickler, die wissen, warum ein bestimmter Puffer eine bestimmte Größe hat und welche Auswirkungen die Wahl des Zeichensatzes auf die Performance hat. Es geht darum, die Kontrolle zurückzugewinnen. Wir sollten nicht Sklaven unserer Werkzeuge sein, sondern ihre Herren.
Software ist niemals fertig, und unsere Lernkurve sollte es auch nicht sein. Die Art und Weise, wie wir mit Daten umgehen, definiert die Qualität unserer Arbeit. Wer bereit ist, den bequemen Weg zu verlassen, wird feststellen, dass die technische Tiefe keine Last ist, sondern eine Quelle der Inspiration. Es ist die Suche nach dem Optimum, die uns antreibt. Es ist der Wille, Systeme zu bauen, die nicht nur funktionieren, sondern die durch ihre Effizienz bestechen. Das ist der Weg des wahren Experten. Wir müssen die alten Zöpfe abschneiden und Platz machen für Architekturen, die der Zukunft gewachsen sind. Nur so können wir den Anforderungen einer datengetriebenen Welt gerecht werden.
Am Ende ist die effiziente Verarbeitung von Daten keine Frage der Syntax, sondern eine Frage der inneren Haltung gegenüber der Maschine.



