Die meisten Datenanalysten begehen einen fundamentalen Fehler, wenn sie an die Vorhersage der Zukunft denken. Sie glauben, es ginge primär um die Rechenleistung oder die Komplexität des neuronalen Netzes. Doch wer sich jemals durch die Trümmer einer gescheiterten Absatzprognose gekämpft hat, weiß, dass die Wahrheit tiefer liegt. Es ist ein weit verbreiteter Irrglaube, dass modernste Deep-Learning-Modelle die klassische Statistik in jedem Fall in den Schatten stellen. Tatsächlich ist R For Time Series Analysis das Paradebeispiel dafür, dass die Architektur des Denkens wichtiger ist als die schiere Masse an Parametern. Während Python oft als das Allzweckmesser der Datenwissenschaft gefeiert wird, bleibt die Sprache R in den Händen derer, die Zeitreihen wirklich verstehen wollen, das präziseste Skalpell. Es geht nicht nur darum, Linien in die Zukunft zu verlängern. Es geht darum, die zugrunde liegende Struktur der Zeit selbst zu sezieren.
Die Illusion der Kausalität in R For Time Series Analysis
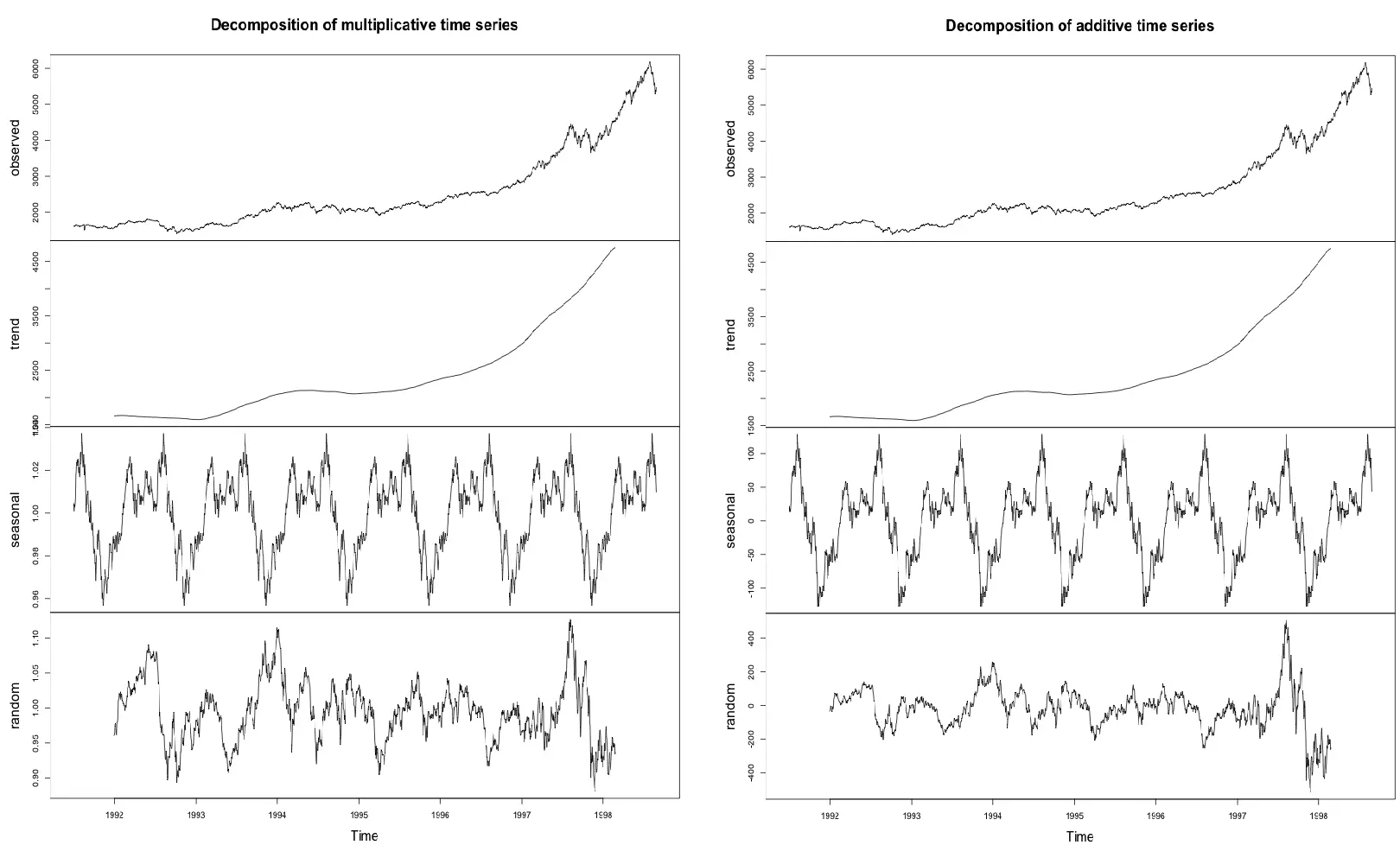
Wer Daten in ein Modell füttert, sucht fast immer nach dem Warum. Doch Zeitreihen sind tückisch. Sie zeigen uns Korrelationen, die oft nichts mit der Realität zu tun haben. Ein klassisches Beispiel aus der ökonometrischen Lehre ist die vermeintliche Korrelation zwischen der Anzahl der Storchennester und der Geburtenrate. In der Welt der statistischen Programmierung ermöglicht uns die Umgebung eine Tiefe der Zerlegung, die viele andere Werkzeuge oberflächlich behandeln. Wir sprechen hier von der Dekomposition in Trend, Saisonalität und Restrauschen. Wenn du ein Modell baust, das den Energieverbrauch in Deutschland für das nächste Jahr vorhersagen soll, kämpfst du gegen Feiertage, Wetterphänomene und wirtschaftliche Zyklen gleichzeitig an. Viele Entwickler werfen einfach ein LSTM-Modell auf das Problem und hoffen auf das Beste. Das ist jedoch gefährlich. Es ist wie das Steuern eines Schiffes im Nebel, bei dem man nur auf das Echolot starrt, ohne die Strömungskarten zu kennen.
Die Stärke dieses spezifischen Feldes liegt in der statistischen Strenge. Ein Modell wie ARIMA ist kein Relikt aus der Computer-Steinzeit. Es ist ein logisches Gerüst, das uns zwingt, Annahmen über Stationarität zu treffen. Wenn eine Zeitreihe nicht stationär ist, also ihr Mittelwert oder ihre Varianz über die Zeit schwankt, sind alle Vorhersagen wertlos. Hier trennt sich die Spreu vom Weizen. In akademischen Kreisen, etwa an der Ludwig-Maximilians-Universität München oder durch die Arbeiten von Rob Hyndman, wird immer wieder betont, dass die Diagnose des Modells wichtiger ist als die Vorhersage selbst. Du musst verstehen, warum dein Modell falsch liegt, bevor du ihm trauen kannst, wenn es richtig liegt. Das System bietet Werkzeuge zur Residuenanalyse, die in ihrer Gründlichkeit unerreicht sind. Wer diese ignoriert, betreibt keine Wissenschaft, sondern digitale Astrologie.
Das Paradoxon der Einfachheit gegen die Komplexität
Es gibt eine wachsende Fraktion von Technik-Enthusiasten, die behaupten, dass klassische Ansätze durch künstliche Intelligenz ersetzt wurden. Das stärkste Gegenargument dieser Skeptiker ist oft die Performance von Black-Box-Modellen bei riesigen Datensätzen. Sie sagen, dass man keine statistischen Tests braucht, wenn man Milliarden von Datenpunkten hat. Doch genau hier liegt der Denkfehler. In der Realität der europäischen Industrie, sei es in der Logistik bei DHL oder in der Fertigung bei Siemens, sind die wirklich wertvollen Datensätze oft klein und verrauscht. Hier versagen massive neuronale Netze kläglich, weil sie Muster im Rauschen finden, die gar nicht existieren. R For Time Series Analysis beweist regelmäßig in Wettbewerben wie der M-Competition, dass einfache, aber gut spezifizierte Modelle oft die hochkomplexen Algorithmen schlagen.
Ich habe Projekte gesehen, in denen Millionen in Hardware investiert wurden, nur um am Ende festzustellen, dass ein simples exponentielles Glättungsmodell die Varianz besser einfängt als ein Serverpark voller GPUs. Das ist kein Zufall. Die mathematische Basis dieser Sprache wurde von Statistikern für Statistiker entwickelt. Das bedeutet, dass die Standardeinstellungen oft auf jahrzehntelanger Forschung basieren und nicht auf dem, was gerade in einem Silicon Valley Blog als Trend gilt. Wenn du die Lyapunov-Exponenten einer Zeitreihe berechnest, um Chaos von Zufall zu unterscheiden, merkst du schnell, dass die Tiefe der Pakete hier eine Qualität erreicht, die man woanders mühsam nachbauen muss. Es ist die eingebaute Vorsicht vor der Überanpassung, die dieses Werkzeug so mächtig macht.
Die verborgene Macht der funktionalen Programmierung
Ein Punkt, der oft übersehen wird, ist die Art und Weise, wie die Sprache den Fluss der Zeit behandelt. Im Gegensatz zur objektorientierten Programmierung erlaubt die funktionale Natur von R eine sehr elegante Handhabung von Transformationen. Wenn man eine Differenzbildung durchführt oder eine Box-Cox-Transformation anwendet, bleibt der Code lesbar und mathematisch nachvollziehbar. Das ist kein rein ästhetischer Aspekt. In regulierten Branchen wie dem Bankwesen oder der Pharmaindustrie ist die Nachvollziehbar jedes Schrittes eine gesetzliche Anforderung. Hier geht es nicht nur darum, dass eine Zahl am Ende herauskommt. Man muss beweisen können, wie diese Zahl zustande kam. Die Tidyverse-Philosophie hat diesen Prozess revolutioniert. Sie hat den Umgang mit Zeitreihen von einer mühsamen Datenmanipulation in einen fast schon erzählerischen Prozess verwandelt. Man beschreibt die Transformationen der Zeitreihe so, wie man ein Rezept schreibt.
Warum Zeitreihen mehr als nur Zahlenfolgen sind
Man darf nicht vergessen, dass hinter jedem Datenpunkt ein reales Ereignis steht. Ein Sensorwert in einer Windkraftanlage in der Nordsee, ein Aktienkurs an der Frankfurter Börse oder die Inzidenzwerte einer Pandemie. Diese Daten haben ein Gedächtnis. Die Autokorrelation ist das mathematische Maß für dieses Gedächtnis. Wer dieses Gedächtnis ignoriert, versteht die Dynamik des Systems nicht. Es gab eine Zeit, in der man glaubte, man könne Finanzmärkte mit einfachen Regressionsmodellen vorhersagen. Die Finanzkrise von 2008 hat schmerzhaft gezeigt, was passiert, wenn man die "Fat Tails" und die Volatilitäts-Cluster ignoriert. Werkzeuge wie GARCH-Modelle, die speziell für solche Phänomene entwickelt wurden, sind in der R-Umgebung so tief verwurzelt, dass sie praktisch zum Standardrepertoire gehören. Es ist die Anerkennung der Instabilität der Welt, die dieses Feld so wertvoll macht.
Die Skepsis gegenüber der Statistik rührt oft von schlechten Erfahrungen her. Jemand hat ein Modell gebaut, das in der Vergangenheit perfekt funktionierte, aber in der Zukunft versagte. Das nennt man das Backtesting-Paradoxon. Man optimiert so lange, bis das Modell die Vergangenheit auswendig gelernt hat. Ein erfahrener Analyst nutzt die in der Sprache verfügbaren Kreuzvalidierungstechniken für Zeitreihen, die eben nicht auf einfachem Zufallssplit basieren. Man darf niemals Daten aus der Zukunft nutzen, um die Vergangenheit zu erklären. Das klingt logisch, wird aber in der Praxis ständig falsch gemacht. Die speziellen Datenstrukturen in R verhindern solche Fehler oft schon durch ihr Design. Sie zwingen dich, die chronologische Ordnung zu respektieren. Das ist keine Einschränkung der Freiheit, sondern eine Sicherung der Integrität.
Man kann die Effizienz eines solchen Ansatzes nicht hoch genug einschätzen. Während andere noch damit beschäftigt sind, ihre Datenumgebungen zu konfigurieren und Abhängigkeiten zu lösen, hat ein Experte hier bereits die erste Spektralanalyse durchgeführt. Die Geschwindigkeit der Erkenntnis ist der wahre Wettbewerbsvorteil. Es geht darum, Hypothesen schnell zu testen und ebenso schnell zu verwerfen. In einer Welt, die immer volatiler wird, ist die Fähigkeit, Signale vom Lärm zu unterscheiden, die wichtigste Fähigkeit überhaupt. Wir leben nicht mehr in einer Zeit, in der man sich auf starre Fünfjahrespläne verlassen kann. Wir brauchen Modelle, die atmen und sich anpassen. Die Flexibilität, die durch Pakete wie fable oder feasts ermöglicht wird, erlaubt genau diese Agilität. Man baut keine Monumente aus Code, sondern lebendige Analyseflüsse.
Wenn wir uns die Zukunft der Vorhersage anschauen, sehen wir eine Verschmelzung. Es ist kein Krieg zwischen Statistik und maschinellem Lernen mehr. Es ist eine Integration. Die besten Ergebnisse erzielen wir, wenn wir die Erklärbarkeit der klassischen Zeitreihenanalyse mit der Flexibilität moderner Algorithmen kombinieren. Das nennt man hybride Modellierung. Man nutzt vielleicht ein neuronales Netz für den nichtlinearen Teil der Daten und ein klassisches Modell für den saisonalen Trend. Diese Brücke schlägt niemand so effizient wie die R-Community. Dort herrscht ein pragmatischer Geist, der das Beste aus beiden Welten vereint. Es ist diese intellektuelle Ehrlichkeit, die mir in vielen aktuellen Hypes fehlt. Man gibt zu, wenn ein Modell unsicher ist. Man quantifiziert die Unsicherheit in Form von Konfidenzintervallen, die tatsächlich eine statistische Bedeutung haben.
Wer also behauptet, dass die Zeit dieses Werkzeugs abgelaufen sei, hat nicht verstanden, worum es bei der Analyse von Zeitreihen wirklich geht. Es geht nicht um das modernste Label oder die coolste Programmiersprache. Es geht um die Wahrheit, die in den Daten verborgen liegt, und um die Demut vor der Unvorhersehbarkeit der Zukunft. Ein Modell ist immer nur eine Karte der Realität, niemals die Realität selbst. Aber mit dem richtigen Instrumentarium ist diese Karte zumindest präzise genug, um uns sicher durch stürmische Zeiten zu führen. Das Verständnis für die tiefe Struktur von Daten über die Zeit hinweg ist keine reine Technik, es ist eine Form der digitalen Alphabetisierung, die heute wichtiger ist denn je.
Die Entscheidung für eine methodische Herangehensweise ist letztlich eine Entscheidung für Qualität vor Geschwindigkeit. Wir werden in den kommenden Jahren sehen, dass die reine Automatisierung der Vorhersage an ihre Grenzen stößt, wo menschliches Expertenwissen und statistische Validierung fehlen. Die Welt ist zu komplex für einfache Wenn-Dann-Logiken. Sie erfordert ein tiefes Eintauchen in die Dynamik von Systemen. Wer diese Dynamik beherrscht, beherrscht die Vorhersage. Und wer die Vorhersage beherrscht, hat die Fäden der Zukunft in der Hand.
Die Zukunft ist kein Schicksal, das uns passiert, sondern eine Zeitreihe, die wir mit dem richtigen Verstand lesen können.



