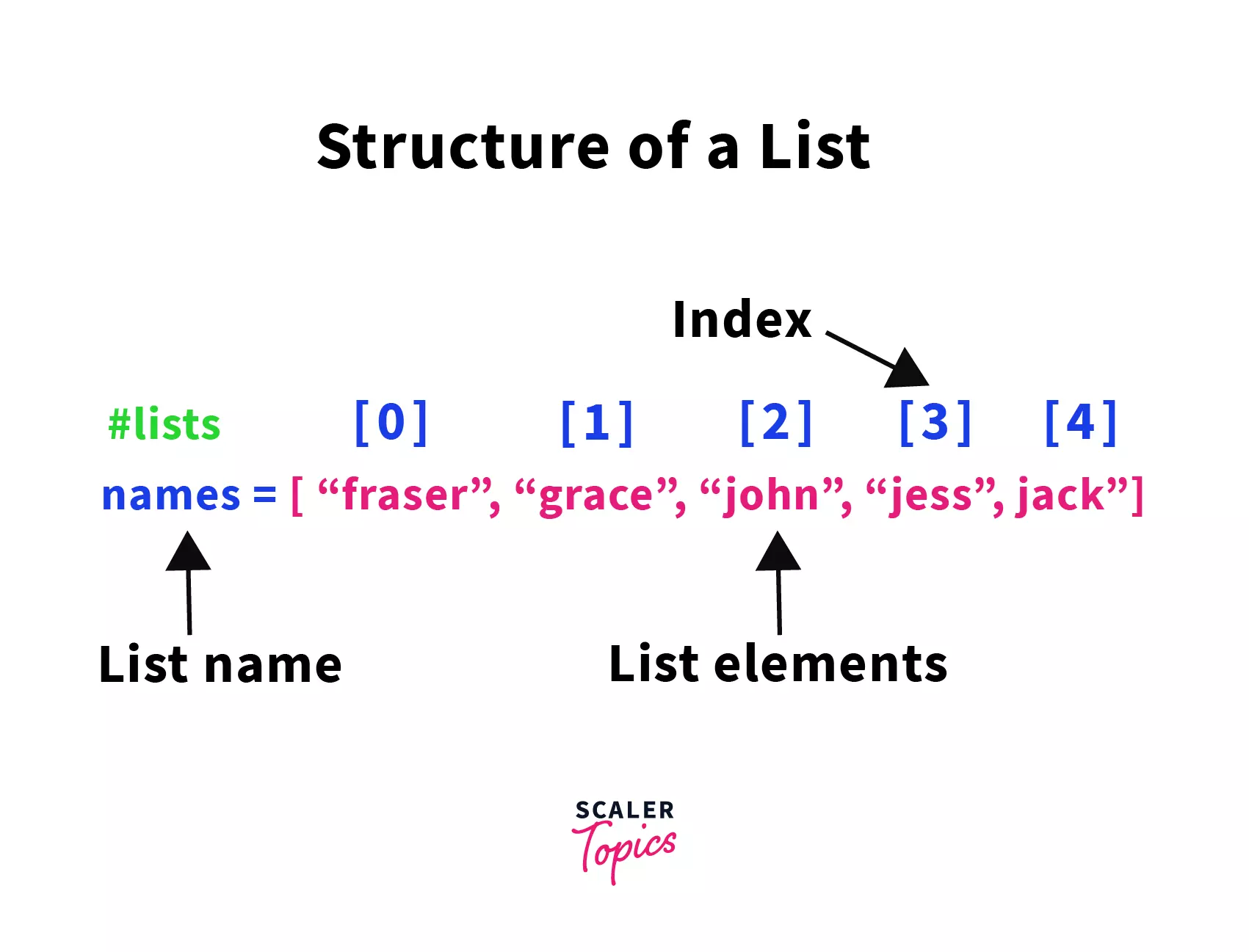
Die Python Software Foundation hat am Dienstag in Beaverton, Oregon, technische Dokumentationen aktualisiert, die spezifische Standards für die Modifikation von Datenstrukturen und das Delete A List Element Python festlegen. Die neuen Richtlinien zielen darauf ab, die Speicherverwaltung in Anwendungen zu optimieren, die massiv parallele Berechnungen durchführen. Laut Van Lindberg, einem ehemaligen Vorstandsmitglied der Foundation, beeinflussen diese methodischen Vorgaben die Art und Weise, wie Entwickler weltweit mit der Programmiersprache interagieren.
Die Aktualisierung erfolgt zu einem Zeitpunkt, an dem die Effizienz von Cloud-Computing-Ressourcen zunehmend in den Fokus von Technologieunternehmen rückt. Das technische Komitee stellte fest, dass unsachgemäße Implementierungen bei der Manipulation von Listen zu signifikanten Latenzzeiten führen können. Das Dokument beschreibt detailliert, wie die interne Speicherverwaltung von CPython auf Löschoperationen reagiert.
Technische Grundlagen Beim Delete A List Element Python
Die interne Struktur einer Liste in Python basiert auf einem dynamischen Array, was bedeutet, dass das Entfernen eines Objekts eine Verschiebung aller nachfolgenden Indizes erfordert. Guido van Rossum, der Schöpfer der Sprache, hat in der offiziellen Python-Dokumentation wiederholt darauf hingewiesen, dass die Zeitkomplexität für das Löschen eines Elements aus der Mitte einer Liste linear ist. Dies wird in der Informatik als $O(n)$ bezeichnet, wobei $n$ die Anzahl der Elemente in der Liste darstellt.
Entwickler nutzen primär drei Mechanismen, um eine solche Operation durchzuführen: die del-Anweisung, die Methode pop und die Methode remove. Die del-Anweisung entfernt ein Element an einem spezifischen Index, während die remove-Methode nach dem ersten Vorkommen eines bestimmten Wertes sucht. Laut Berichten von GitHub-Analysten führt die Wahl der falschen Methode in großen Produktionsumgebungen häufig zu Performance-Einbußen.
Unterschiede In Der Speicherallokation
Wenn ein Programm ein Element am Ende der Liste entfernt, bleibt die Zeitkomplexität konstant bei $O(1)$. Dies liegt daran, dass keine nachfolgenden Elemente im Speicher verschoben werden müssen. Die Python Software Foundation betont, dass die Wahl des Index die Effizienz des gesamten Algorithmus maßgeblich bestimmt.
Ein illustratives Beispiel zeigt, dass das Löschen des ersten Elements in einer Liste mit einer Million Einträgen das Verschieben von 999.999 Zeigern erfordert. Ingenieure bei Google haben in technischen Blogs dokumentiert, dass solche Operationen bei häufiger Wiederholung die CPU-Last unnötig erhöhen. Sie empfehlen stattdessen die Verwendung von collections.deque für Szenarien, in denen Elemente oft an beiden Enden der Struktur manipuliert werden.
Optimierungsstrategien Und Algorithmische Alternativen
In der Softwareentwicklung hat sich die Praxis etabliert, Listen nicht direkt während einer Iteration zu verändern. Das Institut für Softwaretechnologie am Deutschen Zentrum für Luft- und Raumfahrt (DLR) warnt in seinen Programmierrichtlinien davor, dass dies zu unvorhersehbarem Verhalten führen kann. Stattdessen schlagen die Experten vor, neue Listen durch sogenannte List Comprehensions zu erstellen, die nur die gewünschten Elemente enthalten.
Diese Methode ist oft schneller, da sie die zugrunde liegende C-Implementierung von Python nutzt. Die Python Software Foundation gibt an, dass die Erstellung einer neuen Liste oft effizienter ist als das wiederholte Delete A List Element Python innerhalb einer bestehenden Struktur. Dies liegt an der Art und Weise, wie der Garbage Collector von Python nicht mehr benötigten Speicher freigibt.
Einsatz Von Filtermethoden
Die integrierte Funktion filter bietet eine weitere Möglichkeit, Elemente basierend auf einer Bedingung auszuschließen. Laut einer Studie der University of California, Berkeley, bevorzugen erfahrene Programmierer funktionale Ansätze, um die Lesbarkeit und Wartbarkeit des Codes zu erhöhen. Diese Ansätze minimieren das Risiko von "Off-by-one"-Fehlern, die bei manueller Indexverwaltung häufig auftreten.
Ein weiterer Aspekt ist die Verwendung von Slicing, um Teile einer Liste zu entfernen. Durch die Zuweisung einer leeren Liste an einen Slice-Bereich können mehrere Elemente gleichzeitig gelöscht werden. Experten von JetBrains berichteten in einer Umfrage unter professionellen Entwicklern, dass diese Technik besonders bei der Bereinigung von Rohdaten zum Einsatz kommt.
Kritik Und Kontroversen Um Die Listenverwaltung
Kritiker der aktuellen Python-Implementierung, darunter Softwarearchitekten von Meta, bemängeln die Performance von Listen bei extrem großen Datenmengen. Sie argumentieren, dass die Sprache für Big-Data-Anwendungen oft auf externe Bibliotheken wie NumPy oder Pandas angewiesen ist. Diese Bibliotheken verwenden spezialisierte Arrays, die in C geschrieben sind und eine effizientere Speicherverwaltung ermöglichen.
Die Diskussion dreht sich vor allem darum, ob Python eine native Unterstützung für effizientere Linked Lists erhalten sollte. Die Kernentwickler haben diesen Vorschlag bisher abgelehnt, mit der Begründung, dass die aktuelle Listenimplementierung für die Mehrheit der Anwendungsfälle den besten Kompromiss darstellt. In der Entwickler-Mailingliste wird regelmäßig über die Balance zwischen Benutzerfreundlichkeit und Geschwindigkeit debattiert.
Ein weiterer Streitpunkt ist die Speicherfreigabe nach dem Löschen großer Mengen an Daten. Es wurde beobachtet, dass Python den Speicher nicht immer sofort an das Betriebssystem zurückgibt. Dies kann in Umgebungen mit begrenzten Ressourcen, wie zum Beispiel in Docker-Containern, zu Problemen führen.
Auswirkungen Auf Die Industrie Und Ausbildung
Die Ausbildung von Softwareentwicklern an deutschen Universitäten wie der TU München legt einen starken Fokus auf das Verständnis dieser grundlegenden Operationen. Professoren betonen, dass ein tiefes Verständnis der Datenstrukturen notwendig ist, um skalierbare Systeme zu bauen. Das Wissen über die Kosten von Operationen in Listen gehört zum Standardrepertoire der Informatikausbildung.
Unternehmen investieren verstärkt in Code-Reviews, um ineffiziente Datenoperationen frühzeitig zu identifizieren. Laut einer Analyse von Stack Overflow ist die Frage nach dem korrekten Entfernen von Listenelementen eine der am häufigsten gestellten Fragen in der Python-Community. Dies unterstreicht die Relevanz einer klaren Dokumentation durch die offiziellen Stellen.
Auch im Bereich der künstlichen Intelligenz spielt die effiziente Datenverarbeitung eine zentrale Rolle. Da Modelle oft Millionen von Datenpunkten verarbeiten, können kleine Ineffizienzen bei der Datenvorbereitung zu stundenlangen Verzögerungen führen. Forscher bei OpenAI nutzen deshalb oft spezialisierte Datenformate, um die Einschränkungen von Standardlisten zu umgehen.
Zukunftsaussichten Und Geplante Verbesserungen
Für die kommenden Versionen von Python, insbesondere Python 3.13 und 3.14, planen die Entwickler weitere Optimierungen am Interpreter. Das Ziel ist es, den Overhead bei der Verwaltung von Objektreferenzen zu reduzieren. Mark Shannon, ein bekannter Kernentwickler, arbeitet im Rahmen des "Faster CPython"-Projekts an Techniken, die auch die Manipulation von Listen beschleunigen könnten.
Es bleibt abzuwarten, ob neue Datentypen in die Standardbibliothek aufgenommen werden, die speziell für das schnelle Löschen und Einfügen optimiert sind. Die Gemeinschaft beobachtet gespannt die Fortschritte bei der Implementierung eines JIT-Compilers (Just-In-Time) für Python. Ein solcher Compiler könnte zur Laufzeit entscheiden, welche Löschmethode für einen gegebenen Kontext am effizientesten ist.
Die Python Software Foundation wird voraussichtlich auf der nächsten PyCon-Konferenz weitere Details zu ihrer Roadmap bekannt geben. Entwickler weltweit sind angehalten, ihre bestehenden Codebasen auf ineffiziente Muster zu prüfen. Die kontinuierliche Verbesserung der Sprache bleibt ein zentraler Faktor für ihre anhaltende Dominanz in der Softwarewelt.



