Statistiker und Datenwissenschaftler an europäischen Forschungseinrichtungen nutzen zunehmend automatisierte Verfahren, um die Unabhängigkeit kategorialer Variablen in großen Datensätzen zu überprüfen. Ein zentrales Instrument in diesem Prozess ist der Chi Square Test Using R, der es ermöglicht, beobachtete Häufigkeiten mit theoretisch erwarteten Werten in einer Kontingenztafel abzugleichen. Die Open-Source-Programmiersprache bietet hierfür spezialisierte Pakete an, die über die Standarddistribution hinausgehen und die Validierung komplexer medizinischer oder soziologischer Studien beschleunigen.
Laut dem Comprehensive R Archive Network (CRAN), dem zentralen Repository für Erweiterungen der Sprache, stieg die Anzahl der Downloads von Paketen zur statistischen Inferenz im vergangenen Jahr stetig an. Forscher verwenden diese Werkzeuge, um festzustellen, ob ein statistisch signifikanter Zusammenhang zwischen zwei nominalskalierten Merkmalen besteht. Die Anwendung findet meist in der klinischen Forschung statt, wo beispielsweise der Erfolg einer Medikation in Abhängigkeit von einer Altersgruppe untersucht wird.
Das statistische Verfahren basiert auf der Berechnung der Testgröße, die die Abweichung zwischen den empirischen Daten und der Nullhypothese misst. Die R Foundation for Statistical Computing in Wien stellt die notwendige Infrastruktur bereit, damit Wissenschaftler weltweit auf standardisierte Funktionen wie chisq.test() zugreifen können. Diese Funktion berechnet automatisch den p-Wert, der als Entscheidungsgrundlage für die Annahme oder Ablehnung einer Hypothese dient.
Methodische Anforderungen Für Den Chi Square Test Using R
Die korrekte Durchführung dieser Analyse erfordert die Erfüllung spezifischer mathematischer Voraussetzungen. Eine der wichtigsten Bedingungen ist die Unabhängigkeit der einzelnen Beobachtungen, was bedeutet, dass jedes Subjekt nur einmal in der Tabelle auftauchen darf. Zudem müssen die erwarteten Häufigkeiten in jeder Zelle der Matrix groß genug sein, um die Aussagekraft der Teststatistik nicht zu gefährden.
Wissenschaftler wie Hadley Wickham, ein führender Entwickler innerhalb der R-Gemeinschaft, betonen die Bedeutung der Datenaufbereitung vor der eigentlichen Berechnung. Daten müssen oft erst bereinigt und in ein Format gebracht werden, das die statistische Software verarbeiten kann. Hierbei greifen Anwender häufig auf das Tidyverse-Ökosystem zurück, um die Tabellenstruktur für die Inferenzstatistik vorzubereiten.
Falls die Zellhäufigkeiten zu gering sind, bietet die Softwareumgebung Alternativen an, die automatisch vorgeschlagen werden. In solchen Fällen erfolgt oft der Rückgriff auf den exakten Test nach Fisher, um Verzerrungen zu vermeiden. Die Dokumentation auf R-project.org beschreibt detailliert, wie das System Warnmeldungen ausgibt, wenn die Annahmen für das asymptotische Verfahren nicht erfüllt sind.
Mathematische Grundlagen Und Implementierung In Der Praxis
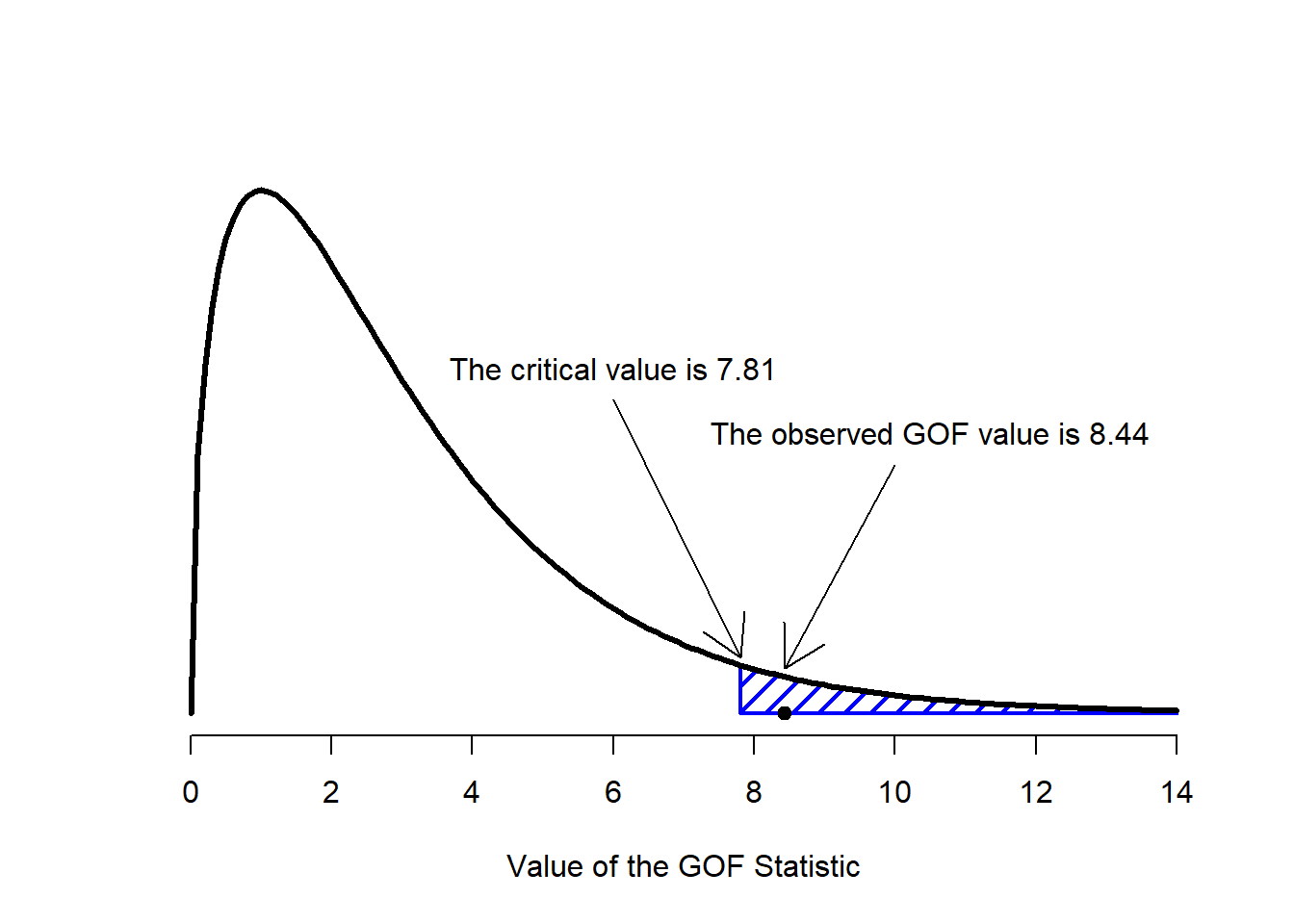
Die Berechnung der Teststatistik folgt einer festen Formel, die die Summe der quadrierten Differenzen zwischen Beobachtung und Erwartung, dividiert durch die Erwartung, bildet. Das System berechnet daraufhin die Freiheitsgrade basierend auf der Anzahl der Zeilen und Spalten der zugrunde liegenden Tabelle. Dieser Wert bestimmt die Form der Verteilung, gegen die das Ergebnis geprüft wird.
In der Praxis geben Nutzer einfache Befehle in die Konsole ein, um komplexe mathematische Operationen in Millisekunden auszuführen. Die Ausgabe enthält neben der Teststatistik auch Informationen über die Stärke des Zusammenhangs, sofern zusätzliche Koeffizienten angefordert werden. Dies reduziert das Risiko menschlicher Rechenfehler, die bei manuellen Kalkulationen in der Vergangenheit häufiger auftraten.
Die Rolle Von Kontingenztabellen
Kontingenztabellen bilden das Fundament für die Untersuchung von Abhängigkeiten zwischen zwei qualitativen Merkmalen. Die Software erlaubt es, diese Tabellen direkt aus Rohdaten zu erstellen oder bestehende Häufigkeitsangaben einzulesen. Durch die Visualisierung dieser Tabellen erhalten Forscher einen ersten Eindruck von der Verteilung ihrer Datenpunkte.
Oft werden diese Tabellen mit Randsummen versehen, um die Berechnung der erwarteten Werte zu erleichtern. Die Software übernimmt diese Schritte im Hintergrund, was die Effizienz in der akademischen Lehre und in kommerziellen Analysen steigert. Die Transparenz des Quellcodes sorgt dabei für eine hohe Replizierbarkeit der Ergebnisse, ein Kernaspekt der modernen Wissenschaft.
Herausforderungen Und Limitationen Statistischer Softwareanwendungen
Trotz der technologischen Fortschritte warnen Experten vor einer unkritischen Anwendung automatisierter Tests. Ein häufiger Kritikpunkt ist die Abhängigkeit vom p-Wert, der allein keine Aussage über die praktische Relevanz eines Effekts zulässt. Kritiker fordern daher vermehrt die Angabe von Effektstärken wie Cramérs V, um die Ergebnisse besser einordnen zu können.
Die American Statistical Association (ASA) veröffentlichte bereits Berichte, die vor einer Fehlinterpretation statistischer Signifikanz warnen. Ein kleiner p-Wert bedeutet nicht zwangsläufig, dass eine Entdeckung von großer Bedeutung ist, sondern lediglich, dass die Daten unter der Nullhypothese unwahrscheinlich sind. Diese Nuance geht in der automatisierten Verarbeitung manchmal verloren, wenn Anwender nur auf die Standardausgabe achten.
Ein weiteres Problem stellt die Qualität der Eingangsdaten dar, da fehlerhafte Kodierungen zu validen, aber inhaltlich falschen Ergebnissen führen. Die Software prüft zwar die mathematische Konsistenz, kann aber keinen Kontext zum ursprünglichen Studiendesign herstellen. Daher bleibt die menschliche Expertise bei der Interpretation der Ausgaben eine notwendige Komponente.
Vergleich Mit Anderen Statistischen Programmiersprachen
Im direkten Vergleich zu kommerziellen Lösungen wie SPSS oder SAS bietet die Umgebung eine höhere Flexibilität bei der Integration in Webanwendungen. Entwickler können statistische Modelle direkt in Dashboards einbinden, was für Echtzeit-Analysen in der Industrie von Vorteil ist. Die Kostenfreiheit der Software trägt zudem zur Demokratisierung der Datenanalyse bei, da auch kleinere Institute Zugang zu Hochleistungswerkzeugen erhalten.
Die Community-Unterstützung gilt als einer der größten Vorteile gegenüber proprietärer Software. Plattformen wie Stack Overflow dokumentieren Millionen von Anfragen zu spezifischen Fehlermeldungen bei der Durchführung statistischer Tests. Diese kollektive Wissensbasis ermöglicht es Anfängern, technische Hürden schnell zu überwinden.
Integration In Den Workflow Der Datenanalyse
Der Chi Square Test Using R ist selten ein isolierter Schritt in einem Forschungsprojekt. Er steht meist am Ende einer explorativen Datenanalyse, nachdem Ausreißer identifiziert und fehlende Werte behandelt wurden. Die Integration in Skripte erlaubt es, den gesamten Prozess von der Datenquelle bis zum finalen Bericht zu automatisieren.
Berichte werden oft mit Werkzeugen wie RMarkdown erstellt, die Text und Code in einem Dokument vereinen. Dies stellt sicher, dass die im Text genannten Zahlen exakt mit den berechneten Werten der Software übereinstimmen. Solche reproduzierbaren Workflows gewinnen in der Begutachtung wissenschaftlicher Publikationen massiv an Bedeutung.
Zukünftige Entwicklungen In Der Automatisierung Der Inferenzstatistik
Die Weiterentwicklung statistischer Software konzentriert sich aktuell auf die Verbesserung der Benutzerfreundlichkeit durch grafische Benutzeroberflächen. Während die klassische Arbeit in der Konsole bestehen bleibt, ermöglichen neue Schnittstellen auch Anwendern ohne Programmierkenntnisse den Zugriff auf komplexe Tests. Projekte wie Jamovi oder JASP nutzen den Kern der Sprache, um eine intuitive Bedienung zu ermöglichen.
Ein weiterer Trend ist die Einbindung von Machine-Learning-Methoden zur Validierung klassischer statistischer Annahmen. Hierbei werden Algorithmen eingesetzt, um automatisch zu prüfen, ob die Verteilung der Daten die Durchführung eines bestimmten Tests rechtfertigt. Dies könnte die Fehlerquote bei der Anwendung statistischer Methoden in der Zukunft signifikant senken.
Es bleibt abzuwarten, wie die wissenschaftliche Gemeinschaft auf die zunehmende Automatisierung reagiert. Die Diskussion über die Aussagekraft von Signifikanztests wird voraussichtlich an Intensität gewinnen, da immer größere Datenmengen zur Verfügung stehen. Forscher müssen weiterhin abwägen, ob eine rein softwaregestützte Analyse den Anforderungen an eine tiefgreifende wissenschaftliche Interpretation gerecht wird.



