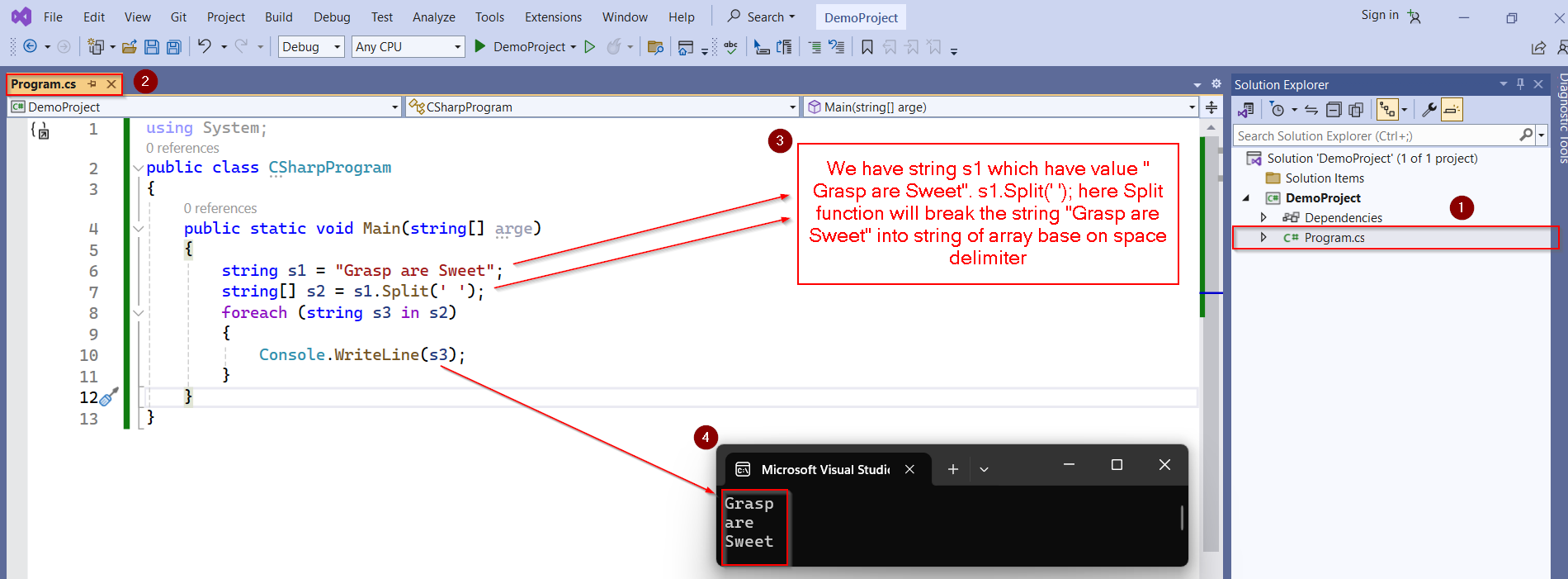
Jeder Entwickler kennt diesen Moment der Frustration. Man sitzt vor einer komplexen Logdatei oder einem Datenstrom und möchte Textbausteine voneinander trennen. Meistens reicht ein einzelnes Zeichen wie ein Komma oder ein Semikolon völlig aus. Doch was passiert, wenn die Trennung komplexer wird? Wenn man eine ganze Zeichenfolge als Trenner braucht, stößt die einfache Split-Methode schnell an ihre Grenzen. Wer in seinem Projekt C# String Split By String sauber umsetzen möchte, muss verstehen, dass der Compiler hier zwischen verschiedenen Überladungen unterscheidet, die nicht immer intuitiv sind. Es geht nicht nur darum, Text zu zerschneiden. Es geht um Speicherverwaltung, Performance und die Vermeidung von leeren Einträgen, die später die Logik zerschießen.
Warum die einfache Methode oft scheitert
Die meisten Anfänger versuchen instinktiv, einen String in die Klammern der Split-Funktion zu werfen. Das knallt sofort. C# erwartet dort primär ein Array von Zeichen. Wenn du aber eine ganze Sequenz wie „[TRENNER]“ hast, musst du dem System explizit sagen, dass dies eine Zeichenkette ist. Ich habe schon unzählige Code-Reviews gesehen, in denen Entwickler kryptische Workarounds bauten, nur weil sie die richtige Überladung nicht kannten. Das führt zu unleserlichem Code. Wartbarkeit sieht anders aus.
Die Typfalle umgehen
In der Welt von .NET ist Typsicherheit heilig. Wenn du eine Zeichenfolge als Separator nutzt, verlangt die Methode meist ein Array dieser Zeichenfolgen. Selbst wenn du nur einen einzigen Trenner hast, musst du ihn in ein Array packen. Das wirkt am Anfang wie unnötiger Overhead. Es ist aber der Weg, den Microsofts Framework vorgibt. Man kann das elegant lösen, indem man die modernen Sprachfeatures nutzt.
C# String Split By String in der Praxis
Wenn du die Aufgabe hast, einen Text anhand einer längeren Zeichenfolge zu zerlegen, ist die Syntax entscheidend. Nehmen wir an, du hast einen String, der durch die Zeichenfolge „---NEXT---“ unterteilt ist. Hier ist der Punkt, an dem viele stolpern. Du musst StringSplitOptions verwenden. Ohne diese Optionen riskierst du, dass dein Resultat mit leeren Fragmenten überflutet wird, falls zwei Trenner direkt hintereinander stehen. Ein sauberer Aufruf von C# String Split By String sieht vor, dass man explizit angibt, ob leere Einträge im Ergebnis-Array verbleiben sollen oder nicht. Meistens willst du sie loswerden. Das spart später Zeit bei der Validierung.
Die Rolle der StringSplitOptions
Es gibt zwei wesentliche Optionen: None und RemoveEmptyEntries. Ich empfehle fast immer die zweite Variante. Stell dir vor, ein Nutzer gibt aus Versehen zwei Leerzeichen oder zwei Trenner ein. Dein Programm würde ohne diese Option versuchen, ein leeres Element zu verarbeiten. Das verursacht oft NullReferenceExceptions oder Logikfehler in nachfolgenden Schleifen. Seit .NET Core und den neueren Versionen von .NET 5 bis 9 gibt es noch TrimEntries. Das ist ein echter Segen. Es entfernt Leerzeichen um die Ergebnisse herum direkt beim Splitten. Das spart den zusätzlichen Aufruf von Trim() in einer Foreach-Schleife.
Performance-Aspekte bei großen Datenmengen
Wer mit Gigabyte-großen Textdateien arbeitet, darf nicht einfach blind drauflos splitten. Jedes Mal, wenn du Split aufrufst, wird ein neues Array im Heap erstellt. Das kostet Speicher. Bei kleinen Strings ist das egal. Bei massiven Datenmengen in einer Cloud-Umgebung treibt das die Kosten für den Garbage Collector in die Höhe. Hier kommen moderne Ansätze wie ReadOnlySpan<char> ins Spiel. Das ist weitaus effizienter als die klassische Methode.
Spans statt klassischer Arrays
Span<T> erlaubt es uns, Teile eines Strings zu betrachten, ohne neue Kopien im Speicher anzulegen. Das ist ein massiver Vorteil für die Performance. In Hochleistungsanwendungen ist das der Standard. Wer heute noch wie vor zehn Jahren programmiert, verschenkt massives Potenzial. Microsoft bietet hierzu exzellente Dokumentationen an. Ein Blick in die offizielle .NET Dokumentation zeigt, wie tiefgreifend diese Optimierungen mittlerweile sind. Es lohnt sich, diese Konzepte frühzeitig zu lernen.
Speicherhunger vermeiden
Jeder String in C# ist unveränderlich. Wenn du also einen Text teilst, entstehen viele kleine neue Strings. In einer Schleife mit tausenden Durchläufen füllt das den Arbeitsspeicher schneller als man denkt. Ich habe Projekte gesehen, bei denen der Server in die Knie ging, nur weil jemand CSV-Dateien mit der falschen Methode parste. Wer hier klug agiert, nutzt Streams oder die erwähnten Spans. Das hält die Applikation flink und reaktionsschnell.
Alternative Wege zur Textanalyse
Manchmal ist C# String Split By String gar nicht das richtige Werkzeug. Wenn die Trenner variieren oder komplexen Mustern folgen, sind Regular Expressions (Regex) oft die bessere Wahl. Aber Vorsicht. Regex ist mächtig, aber auch langsam. Für einfache statische Trennzeichen ist die normale Methode immer vorzuziehen. Regex verbraucht deutlich mehr CPU-Zyklen. Man sollte es nur nutzen, wenn man es wirklich braucht.
Wann Regex sinnvoll ist
Stell dir vor, dein Trenner ist nicht immer gleich. Manchmal ist er großgeschrieben, manchmal klein. Oder er enthält variable Zahlen. Dann hilft die statische Aufteilung nicht weiter. Mit Regex.Split kannst du Muster definieren. Das ist flexibel. Aber ich warne davor, Regex für alles zu benutzen. Es macht den Code schwer lesbar für Kollegen, die nicht täglich mit Mustern arbeiten. Schlichtheit schlägt Komplexität fast immer.
Häufige Fehler und wie man sie behebt
Ein klassischer Fehler ist das Vergessen der Groß- und Kleinschreibung. Wenn dein Trenner „UND“ ist, der Text aber „und“ enthält, wird nichts passieren. Du musst dem System sagen, wie es damit umgehen soll. In modernen C#-Versionen kannst du einen StringComparison-Enum übergeben. Das macht den Code robust gegenüber kleinen Tippfehlern in den Quelldaten. Ein weiterer Fehler ist das harte Codieren von Pfadtrennern. Wer Pfade zerlegen will, sollte niemals einen festen String wie Backslash verwenden. Dafür gibt es Path.DirectorySeparatorChar. Das sorgt dafür, dass dein Code auch auf Linux-Servern läuft. Portabilität ist in der heutigen Softwareentwicklung ein Muss.
Probleme mit Zeilenumbrüchen
Ein ganz spezielles Thema sind Zeilenumbrüche. Windows nutzt \r\n, während Linux \n bevorzugt. Wenn du eine Datei zeilenweise splitten willst, musst du beide Varianten berücksichtigen. Ein einfaches Splitten nach einem harten String wird auf dem falschen Betriebssystem scheitern. Hier ist es ratsam, ein Array von Trennern zu definieren, das beide Möglichkeiten abdeckt. Das ist defensives Programmieren. Es schützt dich vor nächtlichen Support-Anrufen, weil die Anwendung in der Cloud plötzlich streikt.
Die Evolution der String-Verarbeitung in .NET
C# hat sich über die Jahre extrem weiterentwickelt. Früher war alles etwas umständlicher. Heute bietet die Sprache Werkzeuge, die früher undenkbar waren. Besonders seit der Einführung von .NET Core wurde viel Wert auf Geschwindigkeit gelegt. Die internen Mechanismen der Textverarbeitung wurden fast komplett neu geschrieben. Wer mehr über die Hintergründe der Performance-Verbesserungen wissen möchte, findet auf dem .NET Blog von Microsoft regelmäßig tiefe Einblicke. Es ist beeindruckend, wie viel Ingenieurskunst in einer scheinbar einfachen Funktion steckt.
Warum wir uns um Details kümmern sollten
Man könnte meinen, ein einfacher Split sei banale Informatik. Doch die Teufel stecken im Detail. Wie geht man mit Unicode-Zeichen um? Was passiert bei verschiedenen Kulturen und Sprachen? Text ist nicht gleich Text. Wer Software für den internationalen Markt schreibt, muss wissen, dass Sortierung und Trennung je nach Region variieren können. Ein erfahrener Entwickler behält diese Dinge im Hinterkopf.
Praktische Beispiele aus dem Entwickleralltag
Ich erinnere mich an ein Projekt, bei dem wir Telemetriedaten von Maschinen auswerten mussten. Die Daten kamen als ein riesiger Klumpen Text an. Die Trennung erfolgte durch eine spezielle Sequenz von Sonderzeichen. Zuerst versuchten wir es klassisch. Die Anwendung war langsam. Der Speicherverbrauch stieg stetig an. Erst als wir auf die effizienten Überladungen umstiegen und unnötige Kopien vermieden, lief das System stabil. Das zeigt, dass theoretisches Wissen direkt die Qualität der Software beeinflusst.
Die Bedeutung von Unit Tests
Wenn du komplexe Trennlogik schreibst, schreib Tests dazu. Teste Grenzfälle. Was passiert bei einem leeren String? Was, wenn der Trenner gar nicht vorkommt? Was, wenn der gesamte String nur aus Trennern besteht? Diese Szenarien werden oft vergessen. Ein guter Entwickler baut sich ein Sicherheitsnetz. Das spart langfristig Zeit. Fehler in der String-Verarbeitung sind oft schwer zu finden, wenn sie erst tief im System auftreten.
Tipps für sauberen Code
Sauberer Code ist lesbarer Code. Benenne deine Variablen vernünftig. Statt das Ergebnis einfach parts zu nennen, nenne es customerDataFields oder logEntryFragments. Das hilft jedem, der deinen Code nach sechs Monaten wieder anfasst. Vermeide es, zu viele Operationen in eine einzige Zeile zu quetschen. Es sieht cool aus, einen riesigen Einzeiler mit Split, Select, Where und ToList zu haben. Aber es ist ein Albtraum beim Debugging. Brich es in logische Schritte auf. Dein zukünftiges Ich wird es dir danken.
Die Wahl des richtigen Trenners
Manchmal hast du die Kontrolle darüber, wie Daten gespeichert werden. Wähle Trenner, die im eigentlichen Inhalt sicher nicht vorkommen. Wenn du Namen speicherst, ist ein Komma riskant. Jemand könnte „Müller, geb. Schmidt“ heißen. Hier sind spezielle Steuerzeichen oder längere, eindeutige Zeichenfolgen besser geeignet. Genau hier spielt die Technik, Text nach ganzen Strings zu trennen, ihre Stärken aus.
Ausblick auf zukünftige Entwicklungen
Mit .NET 10 und darüber hinaus wird der Fokus noch stärker auf Null-Allokation liegen. Das bedeutet, dass wir immer mehr Werkzeuge bekommen, um Text zu verarbeiten, ohne den Speicher überhaupt zu belasten. Die Richtung ist klar: Effizienz ohne Kompromisse bei der Lesbarkeit. Es bleibt spannend zu sehen, welche neuen Möglichkeiten uns die C#-Compiler-Teams in Redmond noch liefern werden. Wer am Ball bleibt, profitiert von diesen Innovationen.
Nächste Schritte für dein Projekt
Du hast nun eine Vorstellung davon, wie man Text in C# professionell zerlegt. Es ist Zeit, das Wissen anzuwenden. Schau dir deinen aktuellen Code an. Gibt es Stellen, an denen du noch mit alten char-Arrays arbeitest, obwohl ein String-Trenner logischer wäre?
- Prüfe deine bestehenden Split-Aufrufe auf unnötige Speicherallokationen.
- Ersetze manuelle
Trim()-Schleifen durch die Nutzung vonStringSplitOptions.TrimEntries. - Implementiere
ReadOnlySpan<char>, wenn du Performance-kritische Parser baust. - Schreibe Unit Tests für deine String-Verarbeitungslogik, um Randfälle abzusichern.
- Nutze die GitHub-Repositorys von Microsoft, um zu verstehen, wie die Profis solche Funktionen intern implementieren.
Wer diese Schritte befolgt, schreibt nicht nur besseren Code, sondern baut robustere Anwendungen. Textverarbeitung ist das Fundament fast jeder Software. Es lohnt sich, hier zum Experten zu werden. Am Ende spart man sich eine Menge Ärger und liefert Software, die wirklich performant ist. Wer hätte gedacht, dass ein einfaches Thema so viel Tiefe bieten kann? Es ist genau diese Detailverliebtheit, die einen guten von einem exzellenten Entwickler unterscheidet.



