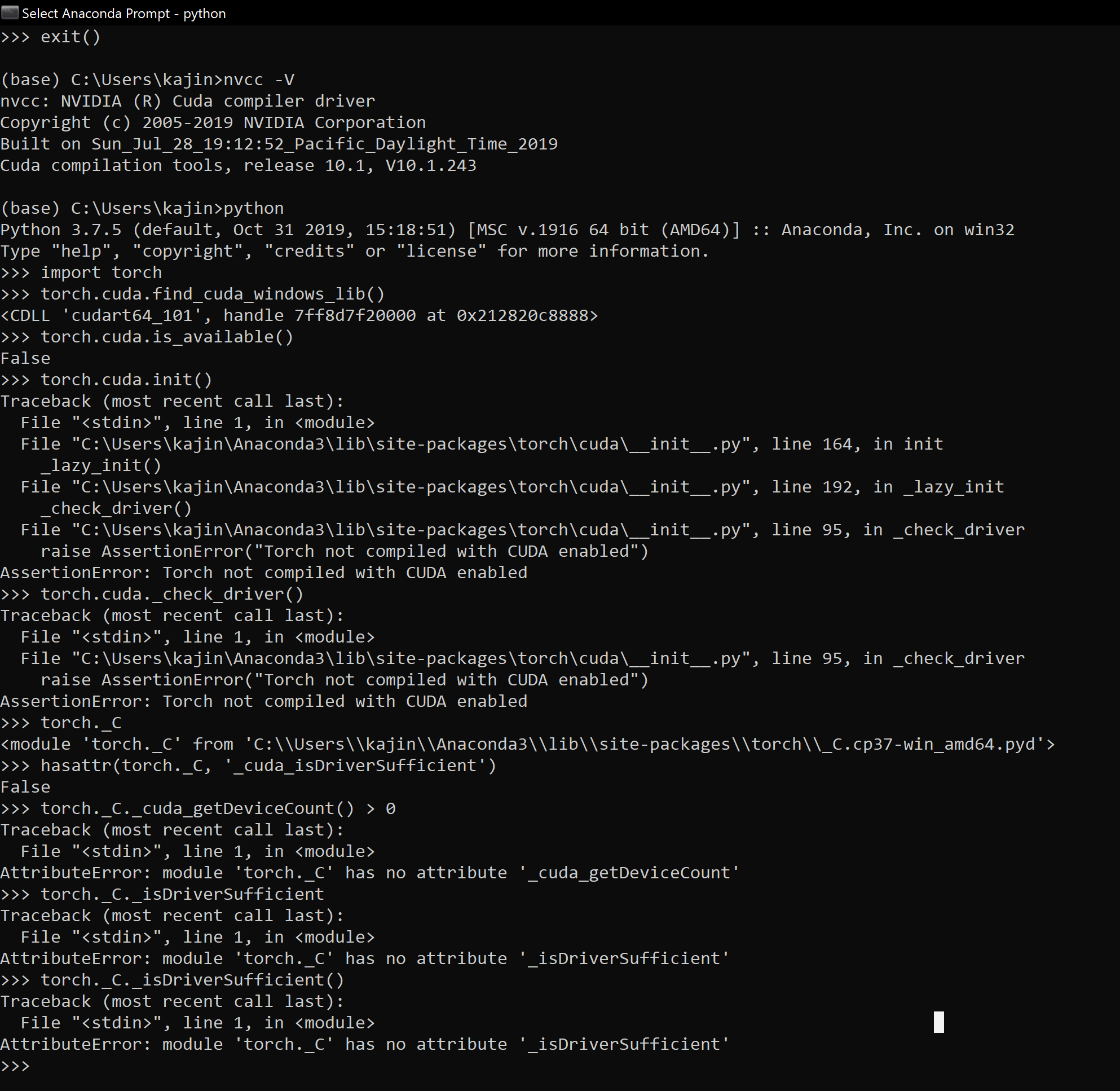
Du hast Stunden damit verbracht, dein Modell zu entwerfen. Die Daten sind sauber. Der Code sieht perfekt aus. Du drückst auf Start und erwartest, dass deine Grafikkarte heiß läuft. Stattdessen starrst du auf eine rote Fehlermeldung in deinem Terminal: AssertionError: Torch Not Compiled With CUDA Enabled. Das ist der Moment, in dem die meisten Entwickler erst mal frustriert Kaffee holen gehen. Ich kenne das. Es passiert ständig, egal ob man Anfänger ist oder seit Jahren neuronale Netze baut. Dieser Fehler ist kein Zeichen für schlechten Code. Er ist ein Zeichen dafür, dass deine Software-Umgebung und deine Hardware nicht dieselbe Sprache sprechen. Dein Betriebssystem denkt, es soll alles auf dem Prozessor berechnen, während dein PyTorch-Skript verzweifelt nach den Rechenkernen deiner NVIDIA-GPU sucht.
Warum tritt dieser Fehler überhaupt auf
Im Kern geht es um ein Missverständnis bei der Installation. PyTorch ist eine Bibliothek, die in verschiedenen Versionen existiert. Es gibt die Standard-Version für die CPU und spezielle Versionen, die mit der CUDA-Schnittstelle von NVIDIA kommunizieren können. Wenn du einfach nur pip install torch eingibst, ohne auf die Details zu achten, lädt das System oft die CPU-Version herunter. Dein Python-Skript versucht dann, mit Befehlen wie .cuda() oder .to('cuda') die Grafikkarte anzusprechen. Die installierte Bibliothek weiß aber gar nicht, was das ist. Sie wurde ohne diese Fähigkeit übersetzt. Ebenfalls in den Schlagzeilen: python list and for loop.
Ein weiterer Grund liegt oft in den Treibern. Deine Hardware braucht den passenden Treiber, und dieser muss wiederum mit dem CUDA Toolkit kompatibel sein, das PyTorch erwartet. Wenn du zum Beispiel ein brandneues Ubuntu-System aufgesetzt hast und direkt mit der Installation von Python-Paketen beginnst, fehlen oft die grundlegenden Grafiktreiber. Ohne diese Treiber kann PyTorch die GPU nicht einmal sehen, selbst wenn sie physisch im Gehäuse steckt. Es ist ein klassisches Problem der Abhängigkeiten, das man nur durch eine strukturierte Vorgehensweise lösen kann.
Die Lösung für AssertionError: Torch Not Compiled With CUDA Enabled
Um dieses Problem zu beheben, musst du die bestehende Installation meistens komplett entfernen. Es bringt selten etwas, einfach eine neue Schicht drüber zu installieren. Du solltest zuerst prüfen, ob dein System die Grafikkarte überhaupt erkennt. Ein schneller Befehl im Terminal wie nvidia-smi zeigt dir, ob die Treiber aktiv sind. Wenn dort eine Fehlermeldung erscheint, musst du bei den Systemtreibern anfangen, nicht bei Python. Sobald die Hardware erkannt wird, folgt die gezielte Installation der richtigen PyTorch-Version. Um das gesamte Bild zu sehen, lesen Sie den detaillierten Bericht von t3n.
Gehe auf die offizielle Seite von pytorch.org. Dort gibt es einen Konfigurator. Du wählst dein Betriebssystem, den Paketmanager wie Conda oder Pip und die passende CUDA-Version aus. Kopiere genau diesen Befehl. Wenn du einfach blind installierst, landest du wieder bei dem Problem, dass die Bibliothek nicht für GPU-Berechnungen vorbereitet wurde. Ich empfehle meistens die Verwendung von virtuellen Umgebungen. Damit verhinderst du, dass sich verschiedene Projekte gegenseitig die Abhängigkeiten zerschießen. Ein sauberes venv oder eine Conda-Umgebung spart dir langfristig Tage an Fehlersuche.
Die Rolle des CUDA Toolkits verstehen
CUDA ist die Rechenarchitektur von NVIDIA. Ohne das passende Toolkit kann dein Prozessor keine komplexen Berechnungen an die Grafikkarte auslagern. Viele Entwickler glauben, es reiche aus, den Grafiktreiber zu installieren. Das stimmt nicht ganz. Während moderne PyTorch-Versionen oft ihre eigenen CUDA-Binärdateien mitbringen, benötigt dein System für die Kompilierung eigener Erweiterungen oft ein lokal installiertes Toolkit.
Es gibt hier eine wichtige Unterscheidung: Die CUDA-Version, die nvidia-smi anzeigt, ist die maximal unterstützte Version deines Treibers. Die Version, die PyTorch nutzt, kann eine andere sein, solange sie niedriger oder gleich der Treiberversion ist. Wenn dein Treiber Version 12.0 meldet, kannst du problemlos ein PyTorch-Paket installieren, das für CUDA 11.8 gebaut wurde. Umgekehrt funktioniert es nicht. Ein veralteter Treiber ist die häufigste Ursache für Frustration in der Deep Learning Community.
Überprüfung der Installation in Python
Nachdem du die Installation durchgeführt hast, solltest du nicht sofort dein riesiges Skript starten. Mach einen kleinen Test. Öffne einen Python-Interpreter. Tippe zwei Zeilen ein. Zuerst importierst du Torch. Danach prüfst du mit torch.cuda.is_available(), ob alles passt. Wenn hier False zurückkommt, ist etwas schiefgelaufen. In diesem Fall hilft oft ein Blick in die Details der installierten Pakete. Mit pip list kannst du sehen, welche Version genau vorliegt. Oft steht dort etwas wie torch 2.1.0+cpu. Das "+cpu" ist das Warnsignal. Du brauchst eine Version, die auf +cu118 oder +cu121 endet. Nur diese Versionen haben die nötigen Instruktionen an Bord, um deine GPU zum Glühen zu bringen.
Häufige Stolperfallen unter Windows und Linux
Unter Windows gibt es oft Probleme mit den Pfadvariablen. Selbst wenn alles installiert ist, findet Python die nötigen DLL-Dateien manchmal nicht. Hier hilft es, die Umgebungsvariablen manuell zu kontrollieren. Linux-Nutzer haben es oft leichter, stolpern aber über Paketkonflikte. Wer zum Beispiel PyTorch über die Standard-Repositories der Distribution installiert, bekommt fast immer die CPU-Version. Die offiziellen Paketquellen von Debian oder Ubuntu sind auf Stabilität getrimmt, nicht auf die neuesten KI-Features.
Ein weiteres Thema ist die Hardware selbst. Nicht jede NVIDIA-Karte unterstützt jede CUDA-Version. Ältere Karten aus der Kepler-Generation werden von aktuellen PyTorch-Releases gar nicht mehr unterstützt. Wenn du versuchst, eine GTX 700er Serie mit CUDA 12 zu betreiben, wirst du scheitern. In solchen Fällen musst du auf ältere Versionen von PyTorch zurückgreifen. Das bedeutet aber auch, dass du auf moderne Features verzichten musst. Es ist ein ständiges Abwägen. Wer professionell im Bereich Computer Vision oder NLP arbeitet, kommt um aktuelle Hardware kaum herum. Die Entwicklung im Bereich der KI-Forschung schreitet so schnell voran, dass alte Setups schnell zum Flaschenhals werden.
Virtuelle Umgebungen als Lebensretter
Ich sehe oft, dass Leute PyTorch global in ihr System installieren. Tu das nicht. Es ist der sicherste Weg, um später Probleme zu bekommen, die man kaum noch entwirren kann. Wenn du ein Projekt für Stable Diffusion hast und ein anderes für Objekterkennung, brauchen diese vielleicht unterschiedliche Versionen. Mit Conda kannst du für jedes Projekt einen eigenen Container erstellen. Das hält dein Hauptsystem sauber.
Ein typischer Workflow sieht so aus: Du erstellst eine Umgebung. Du aktivierst sie. Du installierst die spezifische CUDA-Version von PyTorch. Wenn etwas nicht klappt, löschst du einfach den Ordner der Umgebung und fängst von vorne an. Das dauert drei Minuten. Ein korrumpiertes System neu aufzusetzen dauert drei Stunden. Effizienz beginnt bei der Ordnung auf der Festplatte. Wer hier schlampt, zahlt später mit Fehlermeldungen, die niemand versteht.
Technische Details zur CUDA-Architektur
Die Architektur hinter der Fehlermeldung ist faszinierend. CUDA steht für Compute Unified Device Architecture. Es ermöglicht, dass Tausende kleiner Rechenkerne gleichzeitig an einem Problem arbeiten. Ein Prozessor hat vielleicht 16 oder 32 Kerne. Eine moderne RTX 4090 hat über 16.000. Für das Training eines neuronalen Netzes ist diese Parallelität lebensnotwig.
Wenn PyTorch kompiliert wird, müssen die C++-Header von CUDA vorhanden sein. Die Entwickler von Facebook (Meta) nehmen uns diesen Schritt meistens ab, indem sie vorkompilierte "Wheels" bereitstellen. Diese enthalten bereits den Maschinencode für verschiedene GPU-Architekturen. Wenn du jedoch eine ganz spezielle Optimierung brauchst oder eine sehr seltene GPU nutzt, musst du Torch vielleicht selbst aus dem Quellcode bauen. Das ist die Königsdisziplin. Hier triffst du dann auf Fehlermeldungen, die noch viel kryptischer sind als unser heutiges Problem. Für 99 Prozent der Nutzer ist der Weg über die offiziellen Binärdateien aber der richtige.
Die Bedeutung der Rechenkapazität
Jede GPU hat eine sogenannte Compute Capability. Eine RTX 3080 hat beispielsweise 8.6. Wenn du eine PyTorch-Version nutzt, die nur bis 7.5 kompiliert wurde, nutzt du nicht das volle Potenzial deiner Karte. Schlimmer noch: Sie könnte gar nicht erst funktionieren. Es ist wichtig, dass die Software die Architektur der Hardware versteht. Nur so können Befehle wie Tensor Cores oder Raytracing-Einheiten für mathematische Berechnungen genutzt werden.
Es gibt gute Ressourcen beim NVIDIA Developer Portal, wo man die genauen Spezifikationen nachlesen kann. Diese Informationen sind wichtig, wenn du die Leistung deines Systems maximieren willst. Ein falsch konfiguriertes System kann 50 Prozent langsamer sein als ein optimal eingestelltes. Das macht bei Trainingszeiten von mehreren Tagen einen gewaltigen Unterschied. Zeit ist in der Forschung Geld.
Strategien für Docker und Cloud-Umgebungen
Wenn du in der Cloud arbeitest, etwa auf AWS oder Google Cloud, nutzt du oft Docker-Container. Hier verschiebt sich das Problem. Du musst sicherstellen, dass der Host-Rechner die NVIDIA-Container-Runtime installiert hat. Ohne diese Brücke kann der Container die GPU des Hosts nicht sehen. Die Fehlermeldung bleibt die gleiche. Der Container denkt, er hat keine GPU.
Die Lösung hier ist die Verwendung von offiziellen NVIDIA-Images als Basis für deine Dockerfiles. Diese sind bereits so konfiguriert, dass alle Pfade stimmen. Du sparst dir das manuelle Installieren von Treibern innerhalb des Containers. Es ist ein sauberer Ansatz für die Produktion. Wenn du dein Modell skalieren willst, ist Docker ohnehin der Standard. Wer manuell auf Servern installiert, verliert den Überblick. Skripte müssen reproduzierbar sein.
Fehlerbehebung in Google Colab oder Kaggle
Selbst auf Plattformen wie Google Colab tritt dieser Fehler manchmal auf. Meistens liegt es daran, dass man vergessen hat, den Laufzeittyp auf "GPU" umzustellen. Standardmäßig laufen die Notebooks auf einer CPU. Du versuchst dann, CUDA-Code auszuführen, und Python meldet den Fehler. Ein einfacher Klick in den Einstellungen löst das Problem.
Manchmal aktualisiert Google die vorinstallierten Bibliotheken. Das kann zu Inkonsistenzen führen. Ein kurzer Check mit !nvidia-smi am Anfang jedes Notebooks sollte zur Gewohnheit werden. So weißt du sofort, welche Hardware dir zugewiesen wurde. Manchmal bekommt man eine alte Tesla T4, manchmal eine schnelle A100. Dein Code sollte flexibel genug sein, um mit beiden klarzukommen.
Warum man PyTorch manchmal doch mit CPU nutzt
Es gibt Szenarien, in denen man die CPU-Version bewusst wählt. Wenn du ein Modell nur für die Inferenz auf einem Server ohne Grafikkarte bereitstellst, ist die GPU-Version unnötiger Ballast. Die Pakete sind riesig. Mehrere Gigabyte nur für die CUDA-Unterstützung. Auf einem kleinen Webserver zählt jeder Megabyte.
In der Entwicklungsphase hingegen ist die GPU fast immer Pflicht. Der Geschwindigkeitsvorteil ist zu groß. Ein Epochentraining, das auf der CPU eine Stunde dauert, erledigt eine moderne GPU in zwei Minuten. Wer diesen Unterschied einmal erlebt hat, will nie wieder zurück. Deshalb ist es so wichtig, die Hürde der Installation schnell zu nehmen. Man will forschen, nicht Treiber konfigurieren.
Alternative Frameworks und CUDA
PyTorch ist nicht allein. TensorFlow oder JAX haben ähnliche Probleme. CUDA ist der gemeinsame Nenner. Überall gilt: Die Versionen müssen harmonieren. Der Vorteil an PyTorch ist die große Community. Wenn du ein Problem hast, findest du meistens innerhalb von Minuten eine Lösung in Foren.
Interessanterweise gibt es Bestrebungen, CUDA-Abhängigkeiten zu reduzieren. Mit Projekten wie ROCm für AMD-Karten versucht man, Alternativen zu schaffen. Bisher ist NVIDIA aber der Platzhirsch. Fast alle wichtigen Paper im Bereich Deep Learning nutzen PyTorch mit CUDA. Wer in diesem Feld arbeitet, kommt an grün-schwarzer Hardware kaum vorbei. Das ist ein Quasi-Monopol, das die Entwicklung einerseits beschleunigt, andererseits aber auch Abhängigkeiten schafft.
Praktische Schritte zur Fehlerbehebung
Wenn du jetzt vor deinem Rechner sitzt und das Problem lösen willst, gehe methodisch vor. Keine Panik. Es ist nur Software.
- Deinstalliere die aktuelle Version:
pip uninstall torch torchvision torchaudio. - Überprüfe deine Hardware:
nvidia-smimuss eine Tabelle mit deiner GPU anzeigen. - Installiere die Treiber neu, falls der Befehl oben nicht funktioniert. Nutze dafür die offizielle NVIDIA-Seite oder bei Linux das Paketmanagement deiner Distribution.
- Besuche die PyTorch-Webseite. Wähle deine Konfiguration.
- Führe den generierten Installationsbefehl aus. Achte darauf, dass du in der richtigen virtuellen Umgebung bist.
- Teste die Installation mit einem Mini-Skript:
import torch; print(torch.cuda.is_available()).
Sollte es danach immer noch haken, liegt es oft an versteckten Python-Installationen. Manchmal nutzt VS Code einen anderen Interpreter als dein Terminal. Überprüfe in deiner IDE genau, welcher Pfad verwendet wird. Es ist ein häufiger Fehler, dass man die Bibliothek in Umgebung A installiert, aber in Umgebung B arbeitet. Das passiert selbst Profis.
Den Blick nach vorne richten
Sobald die Hardware läuft, beginnt der eigentliche Spaß. Du kannst Modelle trainieren, Bilder generieren oder Texte analysieren. Die Hürde der Installation ist nur der erste Test deiner Geduld. Deep Learning erfordert viel davon. Nicht nur bei der Einrichtung, sondern auch beim Hyperparameter-Tuning oder beim Warten auf die Konvergenz der Loss-Kurve.
Ich habe gelernt, dass eine saubere Dokumentation des eigenen Setups Gold wert ist. Schreib dir auf, welche Versionen du nutzt. Erstelle eine requirements.txt oder eine environment.yml. Wenn du in sechs Monaten zu deinem Projekt zurückkehrst, wirst du dir selbst danken. Nichts ist frustrierender, als funktionierenden Code zu haben, den man mangels passender Umgebung nicht mehr starten kann.
Ehrlich gesagt ist die Fehlermeldung nervig, aber sie ist auch ein guter Lehrer. Sie zwingt dich dazu, die Schichten deines Systems zu verstehen. Du lernst den Unterschied zwischen User-Space und Kernel-Space kennen. Du verstehst, wie Bibliotheken mit Hardware kommunizieren. Das ist Wissen, das dich zu einem besseren Entwickler macht. Wer nur auf "Play" drückt, lernt nichts. Wer Probleme löst, wächst.
In der Welt der künstlichen Intelligenz ist Stillstand gleichbedeutend mit Rückschritt. Die Hardware entwickelt sich so schnell, dass man ständig am Ball bleiben muss. Aber die Grundlagen der Software-Installation bleiben gleich. Ein Verständnis für Abhängigkeiten und Versionierung ist zeitlos. Es schützt dich vor den meisten Fallstricken, denen Anfänger begegnen.
Was man bei hartnäckigen Fällen tun kann
Wenn alle Standardlösungen versagen, gibt es noch die Möglichkeit, auf fertige Docker-Container aus der NVIDIA NGC Catalog zurückzugreifen. Diese Container sind von NVIDIA selbst optimiert. Sie enthalten alles: Treiber-Interfaces, CUDA, cuDNN und PyTorch. Du musst nur Docker installieren und den Container starten. Es ist die "nukleare Option", wenn gar nichts mehr geht.
Oft liegt das Problem auch an einer beschädigten Anaconda-Installation. Conda versucht manchmal, Abhängigkeiten zu lösen und installiert dabei veraltete Pakete, um Konflikte zu vermeiden. Hier hilft ein conda clean --all oder gleich eine Neuinstallation von Miniconda. Ich bevorzuge Miniconda, weil es schlanker ist und man die volle Kontrolle über jedes installierte Paket behält. Das große Anaconda-Paket schleppt zu viel Ballast mit sich herum, den man im Deep Learning Alltag selten braucht.
Letztlich ist das Ziel, dass du dich auf deine Modelle konzentrieren kannst. Die Technik unter der Haube sollte unsichtbar sein. Aber wie bei einem Rennwagen muss man manchmal selbst unter die Motorhaube schauen, wenn der Motor stottert. Wenn du die oben genannten Schritte befolgst, wird dein System bald wieder einsatzbereit sein. Die Rechenleistung deiner GPU wartet darauf, genutzt zu werden. Lass dich nicht von einer Zeile Text im Terminal aufhalten. Du hast jetzt das Werkzeug, um das Problem dauerhaft aus der Welt zu schaffen. Viel Erfolg beim Training deiner nächsten großen Idee.



